Celosvětová síť je komplexním a konečným zdrojem všech dat, která jsou v ní k dispozici. Rychlý rozvoj, který internet zaznamenal v posledních třech desetiletích, byl bezprecedentní. Výsledkem je, že web se každý den připojuje se stovkami terabajtů dat.
Všechna tato data mají pro někoho nějakou hodnotu. Například vaše historie procházení má význam pro aplikace sociálních médií, protože ji používají k personalizaci reklam, které vám zobrazují. A i pro tato data existuje velká konkurence; o několik MB více dat může dát podnikům podstatný náskok před jejich konkurencí.
Dolování dat pomocí Pythonu
Abychom pomohli těm z vás, kteří začínají se škrábáním dat, připravili jsme tuto příručku, ve které si ukážeme, jak škrábat data z webu pomocí knihovny Python and Beautiful soup Library.
Předpokládáme, že již máte středně pokročilé znalosti jazyka Python a HTML, protože s těmito dvěma pracujete podle pokynů v této příručce.
Buďte opatrní, na kterých webech zkoušíte své nově nalezené dovednosti v těžbě dat, protože mnoho webů to považuje za rušivé a vědí, že by to mohlo mít následky.
Instalace a příprava knihoven
Nyní použijeme dvě knihovny, které budeme používat: knihovnu požadavků pythonu pro načítání obsahu z webových stránek a knihovnu Beautiful Soup pro skutečný škrábací bit procesu. Existují alternativy k BeautifulSoup, pamatujte, a pokud jste obeznámeni s některým z následujících, můžete je místo toho použít: Scrappy, Mechanize, Selenium, Portia, kimono a ParseHub.
Knihovnu požadavků lze stáhnout a nainstalovat pomocí příkazu pip, jak je uvedeno níže:
# požadavky na instalaci pip3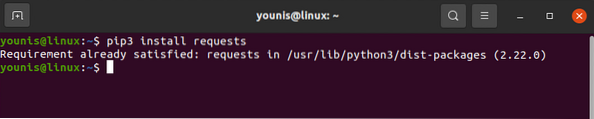
Knihovna požadavků by měla být nainstalována na vašem zařízení. Podobně si stáhněte také BeautifulSoup:
# pip3 nainstalujte beautifulsoup4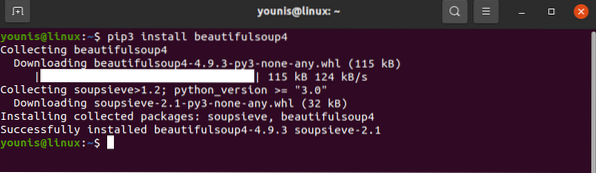
S tím jsou naše knihovny připraveny na nějakou akci.
Jak již bylo zmíněno výše, knihovna požadavků nemá jiné využití než načítání obsahu z webových stránek. Knihovna BeautifulSoup a knihovny požadavků mají místo v každém skriptu, který budete psát, a musí být před každým importovány následujícím způsobem:
$ požadavky na import$ z bs4 importuje BeautifulSoup jako bs
Tím se do požadovaného klíčového slova přidá požadované klíčové slovo, které signalizuje Pythonu význam klíčového slova, kdykoli se zobrazí výzva k jeho použití. Totéž se stane s klíčovým slovem bs, i když zde máme výhodu přiřazení jednoduššího klíčového slova pro BeautifulSoup.
webová stránka = požadavky.získat (URL)Výše uvedený kód načte adresu URL webové stránky a vytvoří z ní přímý řetězec a uloží jej do proměnné.
$ webcontent = webová stránka.obsahVýše uvedený příkaz zkopíruje obsah webové stránky a přiřadí jej proměnnému webovému obsahu.
S tím jsme skončili s knihovnou požadavků. Zbývá už jen změnit možnosti knihovny požadavků na možnosti BeautifulSoup.
$ htmlcontent = bs (webcontent, „html.analyzátor “)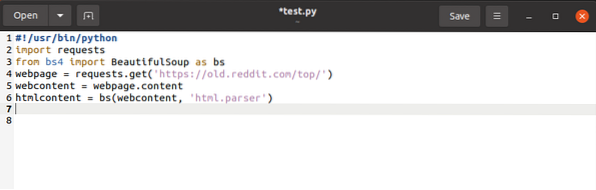
Tím se analyzuje objekt požadavku a změní se na čitelné objekty HTML.
Když je o to vše postaráno, můžeme přejít ke skutečnému škrábání.
Škrábání webu pomocí Pythonu a BeautifulSoup
Pojďme dál a podívejme se, jak můžeme pomocí aplikace BeautifulSoup škrábat datové objekty HTML.
Pro ilustraci příkladu, zatímco vysvětlujeme věci, budeme pracovat s tímto fragmentem html:
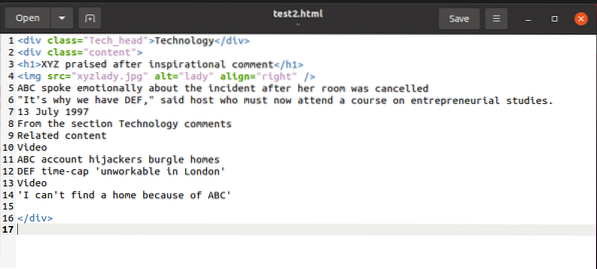
K obsahu tohoto úryvku můžeme přistupovat pomocí aplikace BeautifulSoup a použít jej v proměnné obsahu HTML, jak je uvedeno níže:
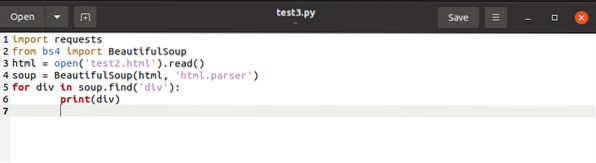
Výše uvedený kód vyhledává všechny pojmenované značky
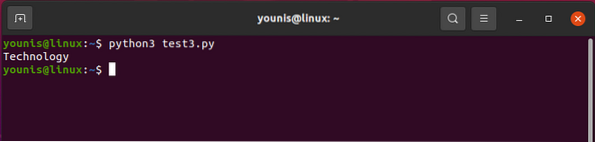
Současné uložení pojmenovaných značek
do seznamu bychom vydali konečný kód jako v: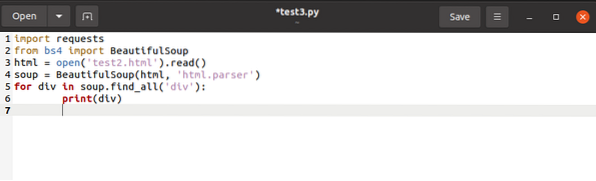
Výstup by se měl vrátit takto:
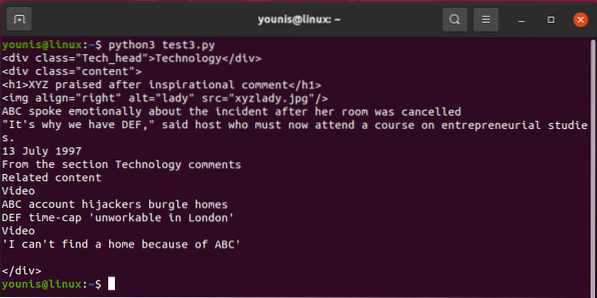
Přivolat jednoho z
Nyní se podívejme, jak vybrat
značky udržující v perspektivě jejich vlastnosti. Chcete-li oddělit a , potřebovali bychom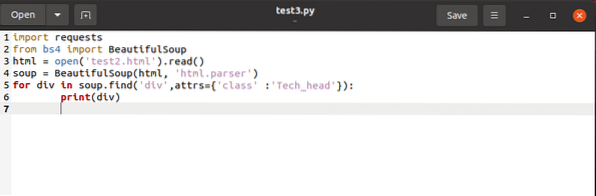
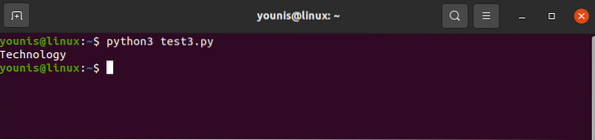
pro div v polévce.find_all ('div', attrs = 'class' = 'Tech_head'):
Toto načte
štítek.Dostali byste:
Technologie
Vše bez značek.
Nakonec se budeme zabývat tím, jak vybrat hodnotu atributu ve značce. Kód by měl mít tuto značku:
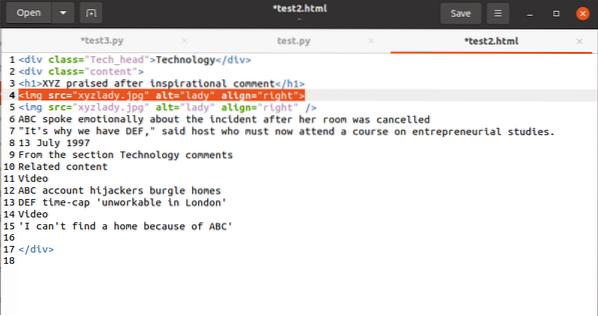

K operaci hodnoty přidružené k atributu src byste použili následující:
obsah html.najít („img“) [„src“]A výstup by se ukázal jako:
„images_4 / a-začátečníci-průvodce-web-škrábání-s-python-a-krásnou-polévkou.jpg "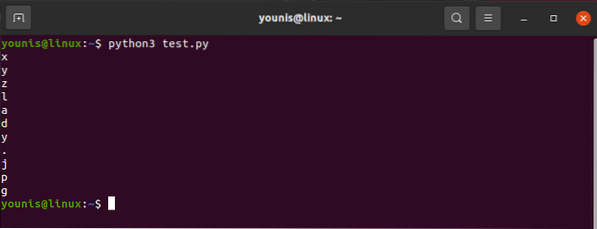
Ach, chlapče, to je určitě spousta práce!
Pokud máte pocit, že vaše znalost jazyka Python nebo HTML není dostatečná, nebo pokud jste prostě zahlceni webovým škrábáním, nebojte se.
Pokud jste firma, která potřebuje pravidelně získávat určitý typ dat, ale neumíte provádět škrábání webu sami, existují způsoby, jak tento problém vyřešit. Ale vězte, že vás to bude stát nějaké peníze. Najdete někoho, kdo za vás provede škrábání, nebo můžete získat prémiovou datovou službu z webů, jako je Google a Twitter, která s vámi bude sdílet data. Tito sdílejí části svých dat pomocí API, ale tato volání API jsou denně omezená. Kromě toho mohou takovéto webové stránky velmi chránit svá data. Mnoho takových webů obvykle nesdílí vůbec žádné své údaje.
Závěrečné myšlenky
Než skončíme, dovolte mi, abych vám to nahlas řekl, pokud to již nebylo zřejmé; Příkazy find (), find_all () jsou vašimi nejlepšími přáteli, když se chystáte škrábat s BeautifulSoup. Ačkoli je zde mnohem víc, co byste měli zvládnout při škrábání hlavních dat pomocí Pythonu, tato příručka by měla stačit těm z vás, kteří právě začínají.


