Indexy pomocí MySQL WorkBench
Nejprve spusťte MySQL Workbench a propojte jej s kořenovou databází.
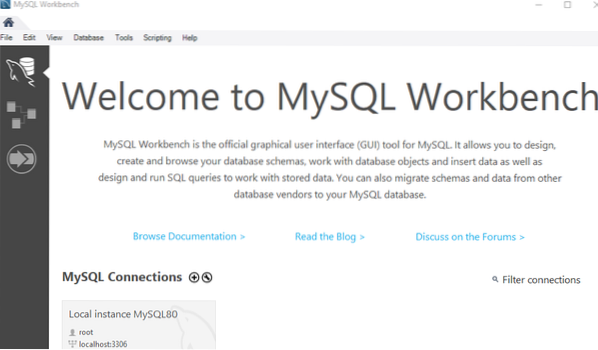
Budeme vytvářet novou tabulku „kontakty“ v databázi „data“, která bude obsahovat různé sloupce. V této tabulce máme jeden primární klíč a jeden sloupec UNIQUE klíče, např.G. ID a e-mail. Zde musíte objasnit, že nemusíte vytvářet indexy pro sloupce UNIQUE a PRIMARY klíčů. Databáze automaticky vytváří indexy pro oba typy sloupců. Takže budeme dělat index 'phone' pro sloupec 'phone' a index 'name' pro sloupce'first_name 'a' last_name '. Spusťte dotaz pomocí ikony Flash na hlavním panelu.
Z výstupu vidíte, že byla vytvořena tabulka a indexy.

Nyní přejděte k pruhu schématu. V seznamu „Tabulky“ najdete nově vytvořenou tabulku.
Zkusme pomocí příkazu ZOBRAZIT INDEXY zkontrolovat indexy pro tuto konkrétní tabulku, jak je znázorněno níže v oblasti dotazu pomocí znaku flash.

Toto okno se objeví najednou. Můžete vidět sloupec „Key_name“, který ukazuje, že klíč patří ke každému sloupci. Protože jsme vytvořili rejstřík „telefonu“ a „jména“, objevuje se také. Můžete vidět další relevantní informace týkající se indexů e.G., posloupnost indexu pro konkrétní sloupec, typ indexu, viditelnost atd.

Indexuje pomocí prostředí příkazového řádku MySQL
Otevřete prostředí klienta příkazového řádku MySQL z počítače. Chcete-li začít používat, zadejte heslo MySQL.

Příklad 01
Předpokládejme, že máme tabulku 'order1' ve schématu 'order' s některými sloupci, které mají hodnoty, jak je znázorněno na obrázku. Pomocí příkazu SELECT musíme načíst záznamy 'order1'.
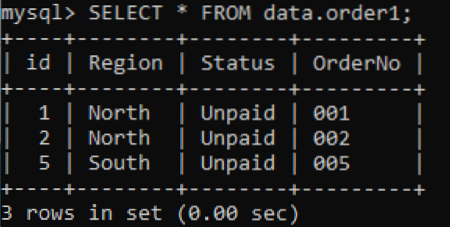
Jelikož jsme pro tabulku 'order1' ještě nedefinovali žádné indexy, nelze to uhodnout. Pokusíme se tedy pomocí příkazu SHOW INDEXES nebo SHOW KEYS zkontrolovat indexy následujícím způsobem:
>> ZOBRAZIT KLÍČE OD objednávky1 V datech;Můžete si všimnout, že tabulka 'order1' má pouze 1 sloupec primárního klíče z níže uvedeného výstupu. To znamená, že zatím nejsou definovány žádné indexy, proto zobrazuje pouze jednořádkové záznamy pro sloupec primárního klíče 'id'.

Podívejme se na indexy libovolného sloupce v tabulce „order1“, kde je viditelnost vypnutá, jak je znázorněno níže.
>> ZOBRAZIT INDEXY Z dat.order1 WHERE VISIBLE = 'NE';
Nyní budeme vytvářet některé UNIQUE indexy v tabulce 'order1'. Pojmenovali jsme tento UNIQUE INDEX jako „rec“ a aplikovali jsme ho na 4 sloupce: id, Region, Status a OrderNo. Vyzkoušejte následující příkaz.
>> VYTVOŘTE JEDINEČNÝ INDEX rec ON data.order1 (id, Region, Status, OrderNo);
Nyní se podívejme na výsledek vytvoření indexů pro konkrétní tabulku. Výsledek je uveden níže po použití příkazu ZOBRAZIT INDEXY. Máme seznam všech vytvořených indexů se stejným názvem „rec“ pro každý sloupec.
>> ZOBRAZIT INDEXY Z objednávky 1 V datech;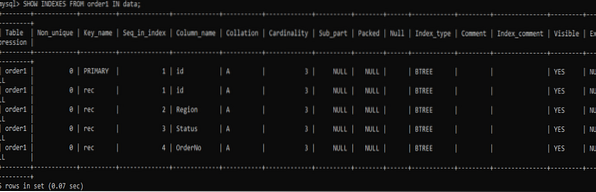
Příklad 02
Předpokládejme novou tabulku „student“ v databázi „data“ se čtyřsloupcovými poli, která mají nějaké záznamy. Načíst data z této tabulky pomocí dotazu SELECT následujícím způsobem:
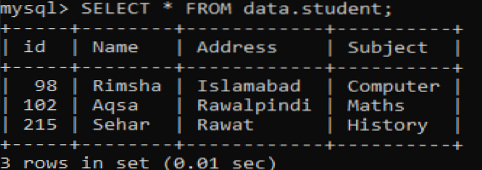
Nejprve načtěte indexy sloupců primárních klíčů pomocí níže uvedeného příkazu SHOW INDEXES.
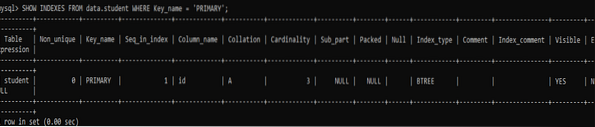
>> ZOBRAZIT INDEXY Z dat.student WHERE Key_name = 'PRIMARY';Můžete vidět, že bude vydávat záznam indexu pro jediný sloupec mající typ 'PRIMARY' kvůli klauzuli WHERE použité v dotazu.
Vytvořme jeden jedinečný a jeden nejedinečný index ve sloupcích „student“ různých tabulek. Nejprve vytvoříme UNIQUE index „std“ ve sloupci „Název“ tabulky „student“ pomocí příkazu CREATE INDEX v klientském prostředí příkazového řádku, jak je uvedeno níže.
>> VYTVOŘENÍ JEDINEČNÉHO INDEXU std ON data.jméno studenta );
Vytvořme nebo přidáme nejedinečný index ve sloupci „Předmět“ tabulky „student“ při použití příkazu ALTER. Ano, používáme příkaz ALTER, protože se používá k úpravě tabulky. Takže jsme upravovali tabulku přidáním indexů do sloupců. Zkusme tedy níže uvedený dotaz ALTER TABLE v prostředí příkazového řádku přidat index 'stdSub' do sloupce 'Subject'.
>> ALTER TABLE data.student PŘIDAT INDEX stdSub (předmět);
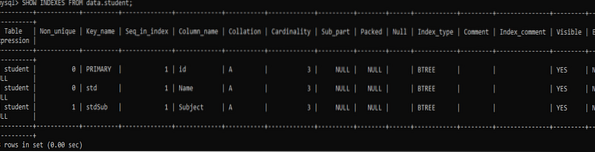
Nyní je řada na kontrole nově přidaných indexů v tabulce „student“ a jejích sloupcích „Název“ a „Předmět“. Zkuste to pomocí níže uvedeného příkazu.
>> ZOBRAZIT INDEXY Z dat.student;Z výstupu můžete vidět, že dotazy přiřadily nejedinečný index ke sloupci „Předmět“ a jedinečný index ke sloupci „Název“. Můžete také zobrazit názvy indexů.
Zkusme příkaz DROP INDEX zrušit index 'stdSub' z tabulky 'student'.
>> DROP INDEX stdSub ON data.student;
Podívejte se na zbývající indexy pomocí stejné instrukce SHOW INDEX jako níže. Nyní jsme ponechali pouze dva indexy, které zůstaly v tabulce „student“ podle níže uvedeného výstupu.
>> ZOBRAZIT INDEXY Z dat.student;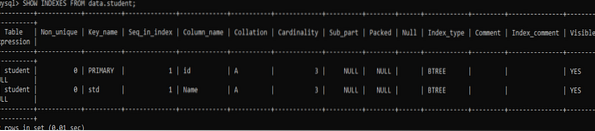
Závěr
Nakonec jsme provedli všechny nezbytné příklady toho, jak vytvořit jedinečné a nejedinečné indexy, zobrazit nebo zkontrolovat indexy a zrušit indexy pro konkrétní tabulku.


