'tab' se používá jako oddělovač v souboru odděleném tabulátory. Tento typ textového souboru je vytvořen k ukládání různých typů textových dat ve strukturovaném formátu. V Linuxu existují různé typy příkazů pro analýzu tohoto typu souboru. Příkaz 'awk' je jedním ze způsobů, jak analyzovat soubor oddělený tabulátory různými způsoby. V tomto tutoriálu byla ukázána použití příkazu 'awk' ke čtení souboru odděleného tabulátory.
Vytvořte soubor oddělený tabulátory:
Vytvořte textový soubor s názvem uživatelů.txt s následujícím obsahem k otestování příkazů tohoto tutoriálu. Tento soubor obsahuje uživatelské jméno, e-mail, uživatelské jméno a heslo.
uživatelů.txt
Jméno E-mail Uživatelské jméno HesloMd. Robin [chráněn e-mailem] robin89 563425
Nila Hasan [chráněno e-mailem] nila78 245667
Mirza Abbas [chráněno e-mailem] mirza23 534788
Aornob Hasan [chráněn e-mailem] arnob45 778473
Nuhas Ahsan [chráněno e-mailem] nuhas34 563452
Příklad-1: Vytiskněte druhý sloupec souboru odděleného tabulátory pomocí volby -F
Následující příkaz 'sed' vytiskne druhý sloupec textového souboru odděleného tabulátory. Tady '-F' Možnost slouží k definování oddělovače polí souboru.
$ uživatelé koček.txt$ awk -F '\ t' 'tisk $ 2' uživatelů.txt
Po spuštění příkazů se zobrazí následující výstup. Druhý sloupec souboru obsahuje e-mailové adresy uživatele, které se zobrazují jako výstup.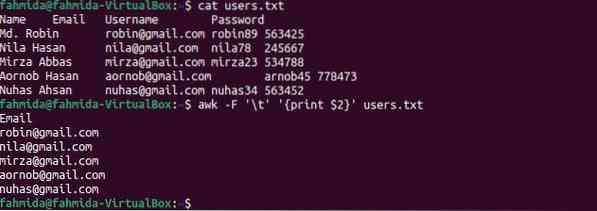
Příklad 2: Vytiskněte první sloupec souboru odděleného tabulátory pomocí proměnné FS
Následující příkaz 'sed' vytiskne první sloupec textového souboru odděleného tabulátory. Tady, FS Proměnná (Oddělovač polí) se používá k definování oddělovače polí souboru.
$ uživatelé koček.txt$ awk 'print $ 1' FS = '\ t' uživatelé.txt
Po spuštění příkazů se zobrazí následující výstup. První sloupec souboru obsahuje jména uživatelů, která se zobrazují jako výstup.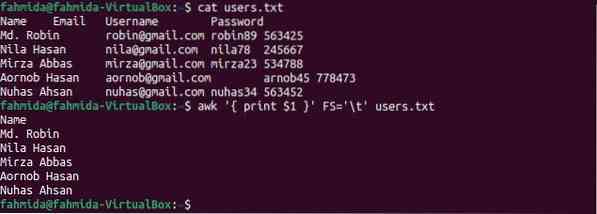
Příklad 3: Tisk třetího sloupce souboru odděleného tabulátory s formátováním
Následující příkaz 'sed' vytiskne třetí sloupec textového souboru odděleného tabulátory s formátováním pomocí FS variabilní a printf. Tady FS proměnná se používá k definování oddělovače pole souboru.
$ uživatelé koček.txt$ awk 'BEGIN FS = "\ t" printf "% 10s \ n", $ 3 uživatelů.txt
Po spuštění příkazů se zobrazí následující výstup. Třetí sloupec souboru obsahuje uživatelské jméno, které zde bylo vytištěno.
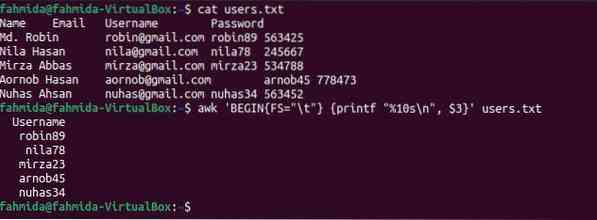
Příklad 4: Tiskněte třetí a čtvrtý sloupec souboru odděleného tabulátory pomocí OFS
OFS (Output Field Separator) se používá k přidání oddělovače polí na výstup. Následující příkaz 'awk' rozdělí obsah souboru na základě oddělovače tabulátorů (\ t) a vytiskne 3. a 4. sloupec pomocí tabulátoru (\ t) jako oddělovače.
$ uživatelé koček.txt$ awk -F "\ t" 'OFS = "\ t" tisknout $ 3, $ 4> ("výstup.Uživatelé txt ").txt
$ kočičí výstup.txt
Po spuštění výše uvedených příkazů se zobrazí následující výstup. 3. a 4. sloupec obsahuje uživatelské jméno a heslo, které zde byly vytištěny.
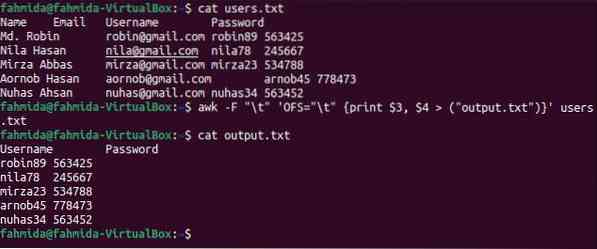
Příklad-5: Nahraďte konkrétní obsah souboru odděleného tabulátory
Funkce sub () se používá v příkazu 'awk k nahrazení. Následující příkaz 'awk' prohledá číslo 45 a nahradí ho číslem 90, pokud v souboru existuje hledané číslo. Po nahrazení bude obsah souboru uložen na výstupu.soubor txt.
$ uživatelé koček.txt$ awk -F "\ t" 'sub (/ 45 /, 90); tisk' uživatelů.txt> výstup.txt
$ kočičí výstup.txt
Po spuštění výše uvedených příkazů se zobrazí následující výstup. Výstup.Soubor txt zobrazuje upravený obsah po použití náhrady. Zde se obsah 5. řádku upravil a 'arnob45' se změnil na 'arnob90'.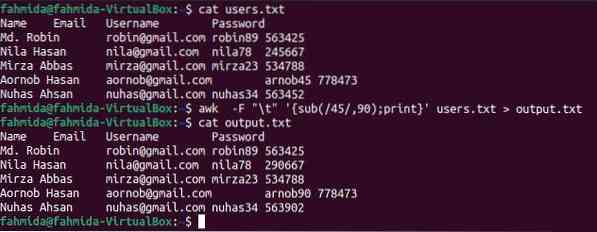
Příklad 6: Přidejte řetězec na začátek každého řádku souboru odděleného tabulátory
V následujícím příkazu „awk“ se volba „-F“ používá k rozdělení obsahu souboru na základě záložky (\ t). OFS používá k přidání čárky (,) jako oddělovače polí na výstup. Funkce sub () slouží k přidání řetězce '- →' na začátek každého řádku výstupu.
$ uživatelé koček.txt$ awk -F "\ t" 'OFS = ","; sub (/ ^ /, "---->"); tisknout uživatele $ 1, $ 2, $ 3.txt
Po spuštění výše uvedených příkazů se zobrazí následující výstup. Každá hodnota pole je oddělena čárkou (,) a na začátek každého řádku je přidán řetězec.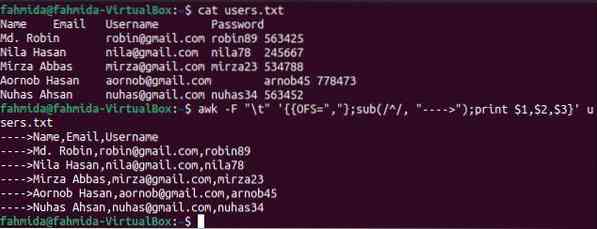
Příklad-7: Nahraďte hodnotu souboru odděleného tabulátory pomocí funkce gsub ()
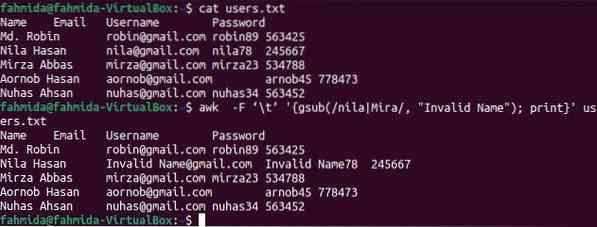
Funkce gsub () se používá v příkazu 'awk' pro globální substituci. Všechny řetězcové hodnoty souboru nahradí místo, kde se shoduje vyhledávací vzor. Hlavní rozdíl mezi funkcemi sub () a gsub () spočívá v tom, že funkce sub () zastaví úlohu nahrazení po nalezení první shody a funkce gsub () prohledá vzor na konci souboru, aby ji nahradil. Následující příkaz „awk“ prohledá v souboru slova „nila“ a „Mira“ globálně a všechny výskyty nahradí textem „Neplatné jméno“, kde se hledané slovo shoduje.
$ uživatelé koček.txt$ awk -F '\ t' 'gsub (/ nila | Mira /, "Neplatné jméno"); uživatelé tisku.txt
Po spuštění výše uvedených příkazů se zobrazí následující výstup. Slovo „nila“ existuje dvakrát ve 3. řádku souboru, který byl ve výstupu nahrazen slovem „Neplatné jméno“.
Příklad 8: Tisk formátovaného obsahu ze souboru odděleného tabulátory
Následující příkaz 'awk' vytiskne první a druhý sloupec souboru s formátováním pomocí printf. Výstup zobrazí jméno uživatele uzavřením e-mailové adresy v závorkách.
$ uživatelé koček.txt$ awk -F '\ t' 'printf "% s (% s) \ n", $ 1, $ 2' uživatelé.txt
Po spuštění výše uvedených příkazů se zobrazí následující výstup.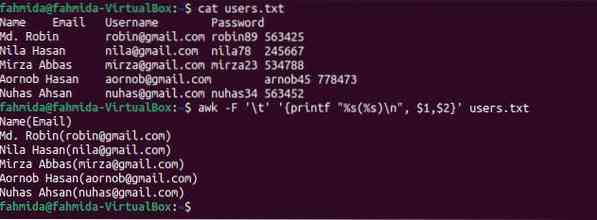
Závěr
Jakýkoli soubor oddělený tabulátory lze snadno analyzovat a vytisknout pomocí jiného oddělovače pomocí příkazu 'awk'. Způsoby analýzy souborů oddělených tabulátory a tisku v různých formátech se v tomto kurzu ukázaly pomocí několika příkladů. V tomto výukovém programu je také vysvětleno použití funkcí sub () a gsub () v příkazu 'awk' k nahrazení obsahu souboru odděleného tabulátory. Doufám, že tento tutoriál pomůže čtenářům snadno analyzovat soubor s oddělovači tabulátorů po správném procvičení příkladů tohoto tutoriálu.


