V tomto článku projdeme základní použití skupiny podle funkce v pythonu pandy. Všechny příkazy jsou prováděny v editoru Pycharm.
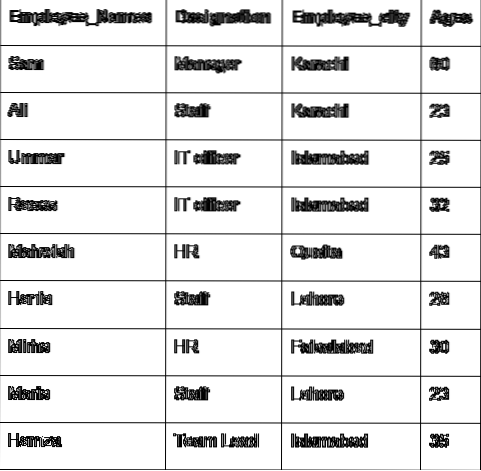
Pojďme diskutovat o hlavní koncepci skupiny pomocí údajů o zaměstnancích. Vytvořili jsme datový rámec s některými užitečnými podrobnostmi o zaměstnanci (Employee_Names, Designation, Employee_city, Age).
Zřetězení řetězců pomocí seskupení podle funkcí
Pomocí funkce groupby můžete zřetězit řetězce. Stejné záznamy lze spojit s „,“ v jedné buňce.
Příklad
V následujícím příkladu jsme setřídili data na základě sloupce Označení zaměstnanců a připojili se k zaměstnancům, kteří mají stejné označení. Funkce lambda je použita na 'zaměstnanci_Name'.
importovat pandy jako pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Označení“: [„Manažer“, „Zaměstnanci“, „Pracovník IT“, „Pracovník IT“, „HR“, „Zaměstnanci“, „HR“, „Zaměstnanci“, „Vedoucí týmu“],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_Age“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ("Označení") ['Jména zaměstnanců'].použít (lambda Employee_Names: ','.připojit se (jména zaměstnanců)
tisk (df1)
Po provedení výše uvedeného kódu se zobrazí následující výstup:
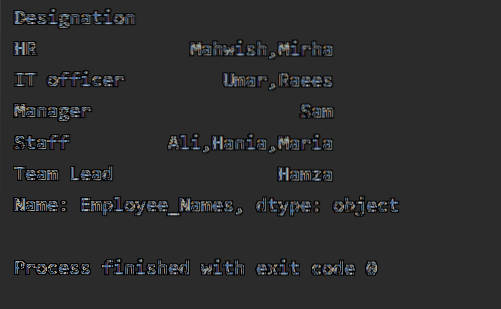
Třídění hodnot ve vzestupném pořadí
Použijte objekt groupby do běžného datového rámce voláním '.to_frame () 'a poté použijte reset_index () pro reindexaci. Seřadit hodnoty sloupců voláním sort_values ().
Příklad
V tomto příkladu seřadíme věk zaměstnance vzestupně. Pomocí následující části kódu jsme načetli 'Employee_Age' ve vzestupném pořadí s 'Employee_Names'.
importovat pandy jako pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Označení“: [„Manažer“, „Zaměstnanci“, „Pracovník IT“, „Pracovník IT“, „HR“, „Zaměstnanci“, „HR“, „Zaměstnanci“, „Vedoucí týmu]],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_Age“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_Names') ['Employee_Age'].součet().zarámovat().reset_index ().sort_values (by = 'Employee_Age')
tisk (df1)
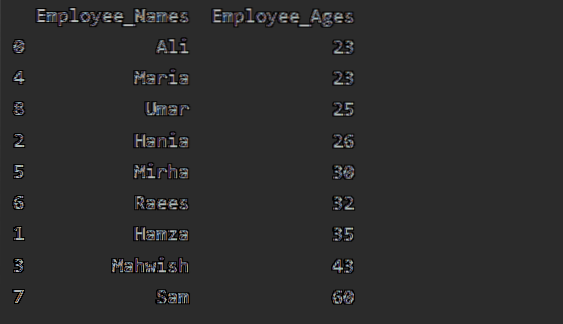
Použití agregátů s groupby
K dispozici je řada funkcí nebo agregací, které můžete použít na datové skupiny, například count (), sum (), mean (), median (), mode (), std (), min (), max ().
Příklad
V tomto příkladu jsme použili funkci 'count ()' s groupby k počítání zaměstnanců, kteří patří do stejného 'Employee_city'.
importovat pandy jako pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Označení“: [„Manažer“, „Zaměstnanci“, „Pracovník IT“, „Pracovník IT“, „HR“, „Zaměstnanci“, „HR“, „Zaměstnanci“, „Vedoucí týmu]],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_Age“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_city').počet()
tisk (df1)
Jak vidíte následující výstup, ve sloupcích Designation, Employee_Names a Employee_Age počítejte čísla, která patří do stejného města:
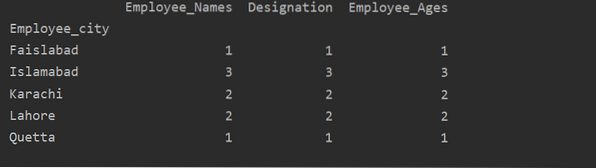
Vizualizujte data pomocí groupby
Pomocí 'import matplotlib.pyplot ', můžete svá data vizualizovat do grafů.
Příklad
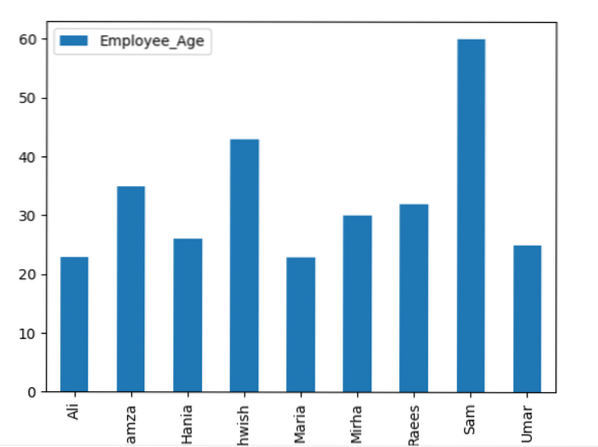
Zde následující příklad vizualizuje 'Employee_Age' s 'Employee_Nmaes' z daného DataFrame pomocí příkazu groupby.
importovat pandy jako pdimport matplotlib.pyplot jako plt
dataframe = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Označení“: [„Manažer“, „Zaměstnanci“, „Pracovník IT“, „Pracovník IT“, „HR“, „Zaměstnanci“, „HR“, „Zaměstnanci“, „Vedoucí týmu“],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_Age“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
plt.clf ()
datový rámec.groupby ('Employee_Names').součet().plot (druh = 'bar')
plt.ukázat()
Příklad
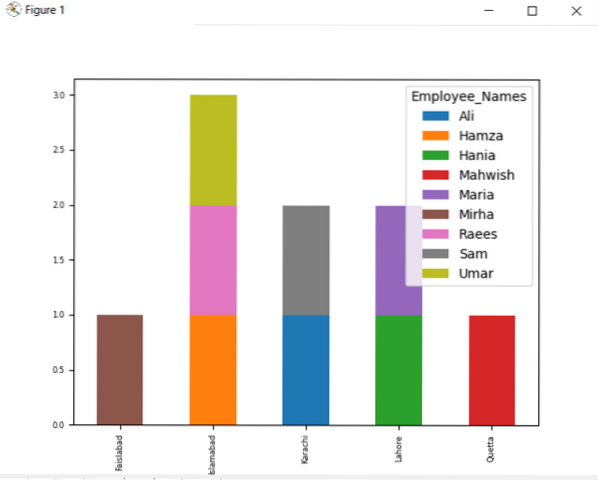
Chcete-li vykreslit skládaný graf pomocí groupby, otočte 'stacked = true' a použijte následující kód:
importovat pandy jako pdimport matplotlib.pyplot jako plt
df = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Označení“: [„Manažer“, „Zaměstnanci“, „Pracovník IT“, „Pracovník IT“, „HR“, „Zaměstnanci“, „HR“, „Zaměstnanci“, „Vedoucí týmu“],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_Age“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df.groupby ([['Employee_city', 'Employee_Names'])).velikost().rozbalit ().plot (kind = 'bar', stacked = True, fontsize = '6')
plt.ukázat()
V níže uvedeném grafu je počet naskládaných zaměstnanců, kteří patří do stejného města.
Změňte název sloupce se skupinou podle
Název agregovaného sloupce s novým upraveným názvem můžete také změnit následujícím způsobem:
importovat pandy jako pdimport matplotlib.pyplot jako plt
df = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Označení“: [„Manažer“, „Zaměstnanci“, „Pracovník IT“, „Pracovník IT“, „HR“, „Zaměstnanci“, „HR“, „Zaměstnanci“, „Vedoucí týmu]],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_Age“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
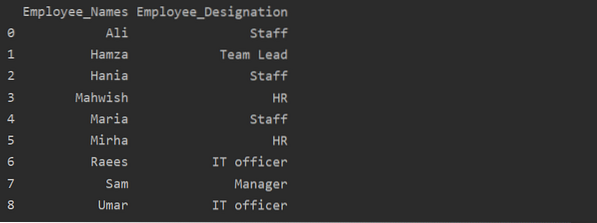
df1 = df.groupby ('Employee_Names') ['Označení'].součet().reset_index (name = 'Employee_Designation')
tisk (df1)
Ve výše uvedeném příkladu se název „označení“ změní na „Employee_Designation“.
Načíst skupinu podle klíče nebo hodnoty
Pomocí příkazu groupby můžete načíst podobné záznamy nebo hodnoty z datového rámce.
Příklad
V níže uvedeném příkladu máme skupinová data založená na „označení“. Poté se skupina „Zaměstnanci“ načte pomocí .getgroup ('Zaměstnanci').
importovat pandy jako pdimport matplotlib.pyplot jako plt
df = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Označení“: [„Manažer“, „Zaměstnanci“, „Pracovník IT“, „Pracovník IT“, „HR“, „Zaměstnanci“, „HR“, „Zaměstnanci“, „Vedoucí týmu]],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_Age“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
extract_value = df.groupby ('Označení')
print (extrahovat_hodnotu.get_group ('Zaměstnanci'))
V okně výstupu se zobrazí následující výsledek:

Přidat hodnotu do seznamu skupin
Podobná data lze zobrazit ve formě seznamu pomocí příkazu groupby. Nejprve seskupte data na základě podmínky. Poté pomocí funkce můžete tuto skupinu snadno zařadit do seznamů.
Příklad
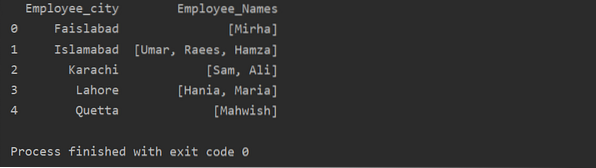
V tomto příkladu jsme do seznamu skupin vložili podobné záznamy. Všichni zaměstnanci jsou rozděleni do skupiny na základě „Employee_city“ a poté pomocí funkce „Lambda“ je tato skupina načtena ve formě seznamu.
importovat pandy jako pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Označení“: [„Manažer“, „Zaměstnanci“, „Pracovník IT“, „Pracovník IT“, „HR“, „Zaměstnanci“, „HR“, „Zaměstnanci“, „Vedoucí týmu“],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_Age“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_city') ['Employee_Names'].použít (lambda group_series: group_series.seznam ()).reset_index ()
tisk (df1)
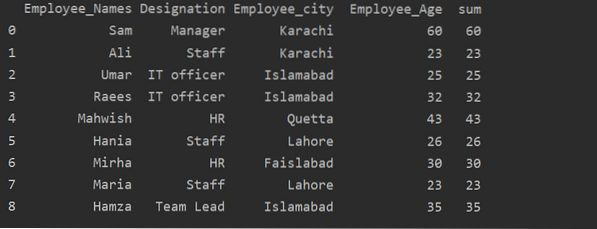
Použití funkce Transformace s groupby
Zaměstnanci jsou seskupeni podle věku, tyto hodnoty se sčítají a pomocí funkce „transformace“ se do tabulky přidá nový sloupec:
importovat pandy jako pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
„Označení“: [„Manažer“, „Zaměstnanci“, „Pracovník IT“, „Pracovník IT“, „HR“, „Zaměstnanci“, „HR“, „Zaměstnanci“, „Vedoucí týmu]],
'Employee_city': ['Karachi', 'Karachi', 'Islamabad', 'Islamabad', 'Quetta', 'Lahore', 'Faislabad', 'Lahore', 'Islamabad'],
„Employee_Age“: [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df ['sum'] = df.groupby (['' Employee_Names ']) [' Employee_Age '].transformace ('součet')
tisk (df)
Závěr
V tomto článku jsme prozkoumali různá použití příkazu groupby. Ukázali jsme, jak můžete data rozdělit do skupin, a použitím různých agregací nebo funkcí můžete tyto skupiny snadno načíst.


