Toto je článek navazující na předchozí. Pokryjeme, jak upřesnit dotaz, formulovat složitější kritéria vyhledávání s různými parametry a porozumět různým webovým formulářům stránky dotazu Apache Solr. Budeme také diskutovat o tom, jak následně zpracovat výsledek hledání pomocí různých výstupních formátů, jako jsou XML, CSV a JSON.
Dotaz na Apache Solr
Apache Solr je navržen jako webová aplikace a služba, která běží na pozadí. Výsledkem je, že jakákoli klientská aplikace může komunikovat se společností Solr odesláním dotazů (zaměření tohoto článku), manipulací s jádrem dokumentu přidáním, aktualizací a odstraněním indexovaných dat a optimalizací základních dat. Existují dvě možnosti - prostřednictvím palubní desky / webového rozhraní nebo pomocí API zasláním odpovídajícího požadavku.
Je běžné používat první možnost pro účely testování a ne pro běžný přístup. Na následujícím obrázku je Dashboard z uživatelského rozhraní Apache Solr Administration s různými formuláři dotazů ve webovém prohlížeči Firefox.
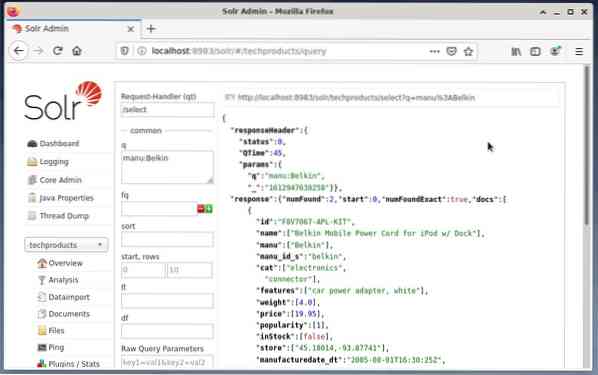
Nejprve z nabídky pod polem pro výběr jádra vyberte položku nabídky „Dotaz“. Dashboard dále zobrazí několik vstupních polí takto:
- Obsluha požadavku (qt):
Definujte, jaký druh požadavku chcete poslat společnosti Solr. Můžete si vybrat mezi výchozí obsluhou požadavků „/ select“ (dotaz indexovaných dat), „/ update“ (aktualizace indexovaných dat) a „/ delete“ (odebrání zadaných indexovaných dat) nebo samostatně definovanou. - Událost dotazu (q):
Definujte, které názvy polí a hodnoty mají být vybrány. - Filtrovat dotazy (FAQ):
Omezte nadmnožinu dokumentů, které lze vrátit, aniž by to ovlivnilo skóre dokumentu. - Pořadí řazení (řazení):
Definujte pořadí řazení výsledků dotazu vzestupně nebo sestupně - Výstupní okno (začátek a řádky):
Omezte výstup na určené prvky - Seznam polí (fl):
Omezuje informace obsažené v odpovědi na dotaz na zadaný seznam polí. - Výstupní formát (hm):
Definujte požadovaný výstupní formát. Výchozí hodnota je JSON.
Kliknutím na tlačítko Spustit dotaz se spustí požadovaný požadavek. Praktické příklady naleznete níže.
Jako druhá možnost, můžete odeslat požadavek pomocí API. Toto je požadavek HTTP, který může být zaslán Apache Solr jakoukoli aplikací. Solr zpracuje požadavek a vrátí odpověď. Zvláštní případ je připojení k Apache Solr pomocí Java API. Toto bylo zadáno samostatnému projektu nazvanému SolrJ [7] - rozhraní Java API bez nutnosti připojení HTTP.
Syntaxe dotazu
Syntaxe dotazu je nejlépe popsána v [3] a [5]. Názvy různých parametrů přímo odpovídají názvům vstupních polí ve formulářích vysvětlených výše. Níže uvedená tabulka uvádí jejich seznam a praktické příklady.
Rejstřík parametrů dotazu
| Parametr | Popis | Příklad |
|---|---|---|
| q | Hlavní parametr dotazu Apache Solr - názvy polí a hodnoty. Jejich skóre podobnosti dokumentuje pojmy v tomto parametru. | Id: 5 auta: * adilla * *: X5 |
| FAQ | Omezte sadu výsledků na nadmnožinu dokumentů, které odpovídají filtru, například definované pomocí analyzátoru dotazů na funkční rozsah | Modelka id, model |
| Start | Odsazení výsledků stránky (začátek). Výchozí hodnota tohoto parametru je 0. | 5 |
| řádky | Odsazení výsledků stránky (konec). Hodnota tohoto parametru je ve výchozím nastavení 10 | 15 |
| třídit | Určuje seznam polí oddělených čárkami, na základě kterých mají být tříděny výsledky dotazu | model vzest |
| fl | Určuje seznam polí, která se mají vrátit pro všechny dokumenty ve výsledkové sadě | Modelka id, model |
| hm | Tento parametr představuje typ zapisovače odpovědí, který jsme chtěli zobrazit výsledek. Hodnota tohoto je ve výchozím nastavení JSON. | JSON xml |
Vyhledávání se provádí pomocí požadavku HTTP GET s řetězcem dotazu v parametru q. Níže uvedené příklady objasní, jak to funguje. Při použití se curl odešle dotaz do Solr, který je nainstalován místně.
- Načíst všechny datové sady ze základních curlů aut http: // localhost: 8983 / solr / cars / dotaz?q = *: *
- Načíst všechny datové sady z hlavních vozů, které mají ID 5 zvlnění http: // localhost: 8983 / solr / cars / dotaz?q = id: 5
- Načtěte model ze všech datových sad hlavních vozů
Možnost 1 (s únikem &): curl http: // localhost: 8983 / solr / cars / dotaz?q = id: * \ & fl = modelMožnost 2 (dotaz jednoduchými klíči):
curl 'http: // localhost: 8983 / solr / cars / dotaz?q = id: * & fl = model ' - Načíst všechny datové sady základních vozů seřazené podle ceny v sestupném pořadí a vygenerovat pouze pole, model a cenu (verze v jednotlivých klíčích): curl http: // localhost: 8983 / solr / cars / query -d '
q = *: * &
sort = cenový popis &
fl = značka, model, cena ' - Načtěte prvních pět datových sad základních vozů seřazených podle ceny v sestupném pořadí a vygenerujte pouze pole, model a cenu (verze s jednoduchým zaškrtnutím): curl http: // localhost: 8983 / solr / cars / query - d '
q = *: * &
řádky = 5 &
sort = cenový popis &
fl = značka, model, cena ' - Načtěte prvních pět datových sad hlavních vozů seřazených podle ceny v sestupném pořadí a vygenerujte pouze pole, model a cenu plus její skóre relevance (verze s jednoduchým zaškrtnutím): curl http: // localhost: 8983 / solr / auta / dotaz -d '
q = *: * &
řádky = 5 &
sort = cenový popis &
fl = značka, model, cena, skóre ' - Vraťte všechna uložená pole a skóre relevance: curl http: // localhost: 8983 / solr / cars / query -d '
q = *: * &
fl = *, skóre '
Kromě toho můžete definovat svůj vlastní obslužný program požadavků, který odešle volitelné parametry požadavku do analyzátoru dotazů, aby bylo možné řídit, jaké informace se vracejí.
Analyzátory dotazů
Apache Solr používá takzvaný analyzátor dotazů - komponentu, která převádí váš vyhledávací řetězec na konkrétní pokyny pro vyhledávač. Analyzátor dotazů stojí mezi vámi a dokumentem, který hledáte.
Solr přichází s řadou typů analyzátorů, které se liší ve způsobu zpracování zadaného dotazu. Analyzátor standardních dotazů funguje dobře pro strukturované dotazy, ale je méně tolerantní k syntaktickým chybám. Zároveň jsou DisMax i Extended DisMax Query Parser optimalizovány pro dotazy podobné přirozenému jazyku. Jsou navrženy tak, aby zpracovávaly jednoduché fráze zadávané uživateli a hledaly jednotlivé výrazy v několika polích pomocí různých váh.
Kromě toho nabízí Solr také takzvané funkční dotazy, které umožňují kombinaci funkce s dotazem za účelem vygenerování konkrétního skóre relevance. Tyto analyzátory se jmenují analyzátor dotazů na funkce a analyzátor dotazů na rozsah funkcí. Níže uvedený příklad ukazuje, že druhá možnost vybere všechny soubory dat pro „bmw“ (uložené v datovém poli make) u modelů od 318 do 323:
curl http: // localhost: 8983 / solr / cars / query -d 'q = make: bmw &
fq = model: [318 TO 323] '
Post-zpracování výsledků
Odesílání dotazů na Apache Solr je jedna část, ale následné zpracování výsledku hledání z druhé. Nejprve si můžete vybrat mezi různými formáty odpovědí - od JSON po XML, CSV a zjednodušený formát Ruby. Jednoduše zadejte odpovídající parametr wt v dotazu. Níže uvedený příklad kódu to ukazuje na načtení datové sady ve formátu CSV pro všechny položky pomocí curl s escaped &:
curl http: // localhost: 8983 / solr / cars / dotaz?q = id: 5 \ & wt = csvVýstupem je seznam oddělených čárkami:

Chcete-li získat výsledek jako data XML, ale pouze dvě výstupní pole vytvářejí a modelují, spusťte následující dotaz:
curl http: // localhost: 8983 / solr / cars / dotaz?q = *: * \ & fl = značka, model \ & wt = xmlVýstup je jiný a obsahuje jak hlavičku odpovědi, tak skutečnou odpověď:
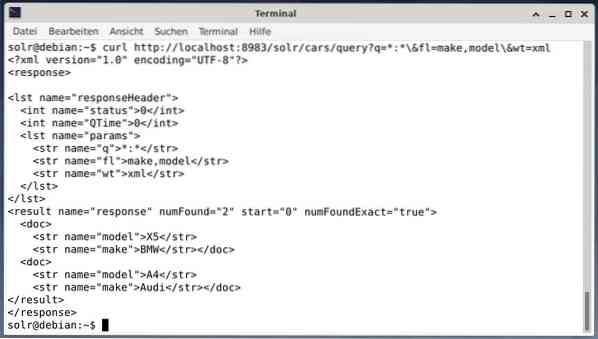
Wget jednoduše vytiskne přijatá data na standardní výstup. To vám umožní následné zpracování odpovědi pomocí standardních nástrojů příkazového řádku. Abychom uvedli několik, obsahuje jq [9] pro JSON, xsltproc, xidel, xmlstarlet [10] pro XML a csvkit [11] pro formát CSV.
Závěr
Tento článek ukazuje různé způsoby odesílání dotazů do Apache Solr a vysvětluje, jak zpracovat výsledek hledání. V další části se naučíte používat Apache Solr k vyhledávání v PostgreSQL, systému správy relačních databází.
O autorech
Jacqui Kabeta je ekolog, vášnivý výzkumník, trenér a mentor. V několika afrických zemích pracovala v IT průmyslu a prostředí nevládních organizací.
Frank Hofmann je IT vývojář, trenér a autor a dává přednost práci z Berlína, Ženevy a Kapského Města. Spoluautor knihy Debian Package Management Book, která je k dispozici u dpmb.org
Odkazy a reference
- [1] Apache Solr, https: // lucene.apache.org / solr /
- [2] Frank Hofmann a Jacqui Kabeta: Úvod do Apache Solr. Část 1, http: // linuxhint.com
- [3] Yonik Seelay: Solr Query Syntax, http: // yonik.com / solr / syntaxe dotazu /
- [4] Yonik Seelay: Solr Tutorial, http: // yonik.com / solr-tutorial /
- [5] Apache Solr: Dotazování na data, Tutorialspoint, https: // www.výukový bod.com / apache_solr / apache_solr_querying_data.htm
- [6] Lucene, https: // lucene.apache.org /
- [7] SolrJ, https: // lucene.apache.org / solr / guide / 8_8 / using-solrj.html
- [8] zvlnění, https: // zvlnění.se /
- [9] jq, https: // github.com / stedolan / jq
- [10] xmlstarlet, http: // xmlstar.sourceforge.síť/
- [11] csvkit, https: // csvkit.readthedocs.io / en / nejnovější /


