Toto je článek navazující na předchozí dva [2,3]. Zatím jsme načetli indexovaná data do úložiště Apache Solr a dotazovali jsme se na ně. Nyní se naučíte, jak připojit systém správy relačních databází PostgreSQL [4] k Apache Solr a provádět v něm vyhledávání pomocí schopností Solr. Díky tomu je nutné provést několik kroků popsaných níže podrobněji - nastavení PostgreSQL, příprava datové struktury v databázi PostgreSQL a připojení PostgreSQL k Apache Solr a hledání.
Krok 1: Nastavení PostgreSQL
O PostgreSQL - krátká informace
PostgreSQL je důmyslný objektově-relační systém pro správu databází. Je k dispozici pro použití a prošel aktivním vývojem již více než 30 let. Pochází z University of California, kde je považován za nástupce Ingres [7].
Od začátku je k dispozici pod otevřeným zdrojovým kódem (GPL), který lze zdarma používat, upravovat a distribuovat. To je široce používán a velmi populární v průmyslu. PostgreSQL byl původně navržen pro provoz pouze na systémech UNIX / Linux a později byl navržen pro provoz na jiných systémech, jako jsou Microsoft Windows, Solaris a BSD. Aktuální vývoj PostgreSQL provádí po celém světě mnoho dobrovolníků.
Nastavení PostgreSQL
Pokud ještě není hotovo, nainstalujte server a klienta PostgreSQL lokálně, například na Debian GNU / Linux, jak je popsáno níže, pomocí apt. Dva články se zabývají PostgreSQL - článek Yunise Saida [5] pojednává o nastavení na Ubuntu. Přesto jen škrábe povrch, zatímco můj předchozí článek se zaměřuje na kombinaci PostgreSQL s příponou GIS PostGIS [6]. Popis zde shrnuje všechny kroky, které pro toto konkrétní nastavení potřebujeme.
# apt install postgresql-13 postgresql-client-13Dále pomocí příkazu pg_isready ověřte, zda běží PostgreSQL. Toto je nástroj, který je součástí balíčku PostgreSQL.
# pg_isready/ var / run / postgresql: 5432 - připojení jsou přijímána
Výstup výše ukazuje, že PostgreSQL je připraven a čeká na příchozí připojení na portu 5432. Pokud není nastaveno jinak, jedná se o standardní konfiguraci. Dalším krokem je nastavení hesla pro uživatele systému UNIX Postgres:
# passwd PostgresMějte na paměti, že PostgreSQL má vlastní databázi uživatelů, zatímco administrativní uživatel PostgreSQL Postgres ještě nemá heslo. Předchozí krok je třeba udělat i pro uživatele PostgreSQL Postgres:
# su - Postgres$ psql -c "ZMĚNIT UŽIVATELE Postgres S HESLEM 'heslo';"
Pro zjednodušení je zvolené heslo pouze heslo a mělo by být nahrazeno bezpečnější frází hesla v jiných systémech než testování. Výše uvedený příkaz změní interní uživatelskou tabulku PostgreSQL. Uvědomte si různé uvozovky - heslo v jednoduchých uvozovkách a dotaz SQL v uvozovkách, které zabrání interpretovi prostředí ve špatném vyhodnocení příkazu. Přidejte také středník za dotaz SQL před uvozovkami na konci příkazu.
Dále se z administrativních důvodů připojte k PostgreSQL jako uživatel Postgres s dříve vytvořeným heslem. Příkaz se nazývá psql:
$ psqlPřipojení z Apache Solr k databázi PostgreSQL se provádí jako uživatelské řešení. Pojďme tedy přidat uživatelské řešení PostgreSQL a nastavit mu odpovídající řešení hesel najednou:
$ CREATE USER solr S PASSWD 'solr';Pro zjednodušení je zvolené heslo pouze solr a mělo by být nahrazeno bezpečnější frází hesla v systémech, které jsou ve výrobě.
Krok 2: Příprava datové struktury
K ukládání a načítání dat je nutná odpovídající databáze. Následující příkaz vytvoří databázi automobilů, která patří uživateli solr a bude použita později.
$ VYTVOŘIT DATABÁZE auta S VLASTNÍKEM = solr;Poté se připojte k nově vytvořeným databázovým vozům jako uživatel solr. Možnost -d (krátká volba pro -dbname) definuje název databáze a -U (krátká volba pro -username) jméno uživatele PostgreSQL.
$ psql -d auta -U solrPrázdná databáze není užitečná, ale strukturované tabulky s obsahem ano. Vytvořte strukturu stolních vozů následovně:
$ CREATE TABLE cars (id int,
udělat varchar (100),
model varchar (100),
popis varchar (100),
barevný varchar (50),
cena int
);
Tabulkové vozy obsahují šest datových polí - id (integer), make (řetězec o délce 100), model (řetězec o délce 100), description (řetězec o délce 100), color (řetězec o délce 50) a cena (celé číslo). Chcete-li mít některá ukázková data, přidejte do tabulkových vozů následující hodnoty jako příkazy SQL:
$ INSERT INTO cars (id, make, model, description, color, price)HODNOTY (1, 'BMW', 'X5', 'Cool car', 'grey', 45000);
$ INSERT INTO cars (id, make, model, description, color, price)
HODNOTY (2, „Audi“, „Quattro“, „závodní auto“, „bílé“, 30000);
Výsledkem jsou dva příspěvky představující šedé BMW X5, které stojí 45 000 USD, popsané jako chladné auto, a bílé závodní auto Audi Quattro, které stojí 30000 USD.
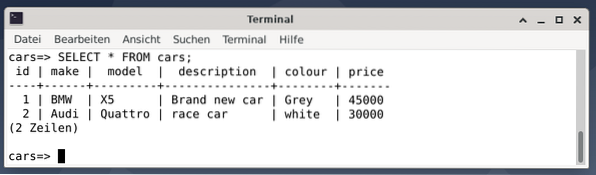
Dále ukončete z konzoly PostgreSQL pomocí \ q, nebo ukončete.
$ \ qKrok 3: Připojení PostgreSQL k Apache Solr
Spojení PostgreSQL a Apache Solr je založeno na dvou částech softwaru - ovladači Java pro PostgreSQL nazvaném ovladač Java Database Connectivity (JDBC) a rozšíření konfigurace serveru Solr. Ovladač JDBC přidává do PostgreSQL rozhraní Java a další položka v konfiguraci Solr říká Solr, jak se připojit k PostgreSQL pomocí ovladače JDBC.
Přidání ovladače JDBC se provádí jako uživatel root následujícím způsobem a ovladač JDBC se nainstaluje z úložiště balíčků Debian:
# apt-get install libpostgresql-jdbc-javaNa straně Apache Solr musí také existovat odpovídající uzel. Pokud to ještě není hotové, vytvořte jako uživatel systému UNIX vozy uzlů následujícím způsobem:
$ bin / solr create -c carsDále rozšířte konfiguraci Solr pro nově vytvořený uzel. Přidejte následující řádky do souboru / var / solr / data / cars / conf / solrconfig.xml:
db-data-config.xmlDále vytvořte soubor / var / solr / data / cars / conf / data-config.xml a uložte do něj následující obsah:
Řádky výše odpovídají předchozímu nastavení a definují ovladač JDBC, určují port 5432 pro připojení k PostgreSQL DBMS jako uživatelské řešení s odpovídajícím heslem a nastavují, aby byl SQL dotaz prováděn z PostgreSQL. Pro zjednodušení je to příkaz SELECT, který popadne celý obsah tabulky.
Poté restartujte server Solr a aktivujte změny. Jako uživatel root proveďte následující příkaz:
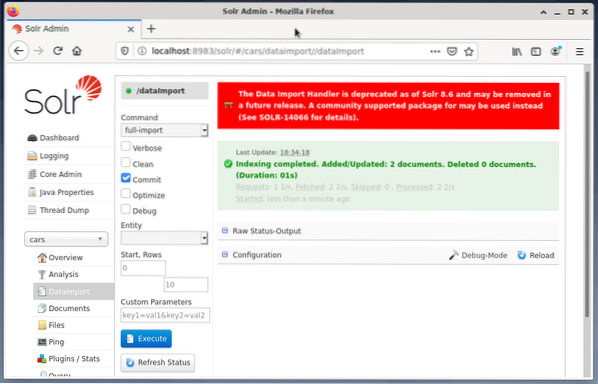
# systemctl restart solrPosledním krokem je import dat, například pomocí webového rozhraní Solr. Pole pro výběr uzlu vybere vozy uzlů, poté z nabídky Uzel pod položkou Dataimport následované výběrem úplného importu z nabídky Příkaz doprava. Nakonec stiskněte tlačítko Spustit. Obrázek níže ukazuje, že společnost Solr úspěšně indexovala data.
Krok 4: Dotazování na data z DBMS
Předchozí článek [3] se zabývá podrobným dotazováním dat, načítáním výsledků a výběrem požadovaného výstupního formátu - CSV, XML nebo JSON. Dotazování na data se provádí podobně jako to, co jste se naučili dříve, a uživatel nevidí žádný rozdíl. Solr provádí veškerou práci v zákulisí a komunikuje s PostgreSQL DBMS připojeným podle definice ve vybraném jádru nebo klastru Solr.
Využití Solr se nemění a dotazy lze odesílat přes administrátorské rozhraní Solr nebo pomocí curl nebo wget na příkazovém řádku. Na server Solr odešlete požadavek Získat s konkrétní adresou URL (dotaz, aktualizace nebo odstranění). Solr zpracuje požadavek pomocí DBMS jako úložné jednotky a vrátí výsledek požadavku. Dále post-process odpověď místně.
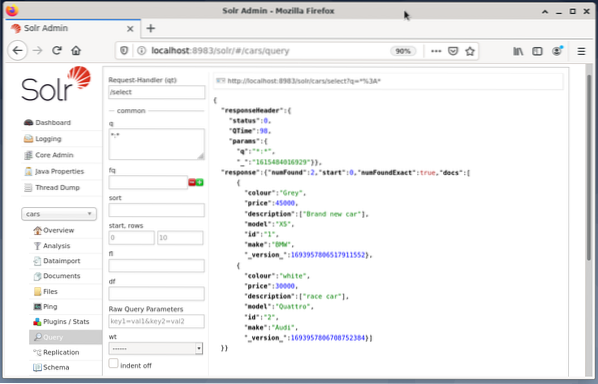
Níže uvedený příklad ukazuje výstup dotazu „/ select?q = *. * ”Ve formátu JSON v administrátorském rozhraní Solr. Data se načítají z databázových vozů, které jsme vytvořili dříve.
Závěr
Tento článek ukazuje, jak dotazovat databázi PostgreSQL z Apache Solr a vysvětluje odpovídající nastavení. V další části této série se naučíte, jak kombinovat několik uzlů Solr do clusteru Solr.
O autorech
Jacqui Kabeta je ekolog, vášnivý výzkumník, trenér a mentor. V několika afrických zemích pracovala v IT průmyslu a prostředí nevládních organizací.
Frank Hofmann je IT vývojář, trenér a autor a dává přednost práci z Berlína, Ženevy a Kapského Města. Spoluautor knihy Debian Package Management Book, která je k dispozici u dpmb.org
Odkazy a reference
- [1] Apache Solr, https: // lucene.apache.org / solr /
- [2] Frank Hofmann a Jacqui Kabeta: Úvod do Apache Solr. Část 1, https: // linuxhint.com / apache-solr-setup-a-uzel /
- [3] Frank Hofmann a Jacqui Kabeta: Úvod do Apache Solr. Dotaz na data. Část 2, http: // linuxhint.com
- [4] PostgreSQL, https: // www.postgresql.org /
- [5] Younis Said: Jak nainstalovat a nastavit databázi PostgreSQL na Ubuntu 20.04, https: // linuxhint.com / install_postgresql_-ubuntu /
- [6] Frank Hofmann: Nastavení PostgreSQL s PostGIS na Debian GNU / Linux 10, https: // linuxhint.com / setup_postgis_debian_postgres /
- [7] Ingres, Wikipedia, https: // en.wikipedia.org / wiki / Ingres_ (databáze)


