Proč je Lucene potřeba?
Hledání je jednou z nejběžnějších operací, které provádíme několikrát denně. Toto vyhledávání může probíhat na více webových stránkách, které existují na webu nebo v hudební aplikaci nebo v úložišti kódu nebo v kombinaci všech těchto. Jeden by si mohl myslet, že jednoduchá relační databáze může také podporovat vyhledávání. Toto je správně. Databáze jako MySQL podporují fulltextové vyhledávání. Ale co webová nebo hudební aplikace nebo úložiště kódů nebo jejich kombinace? Databáze nemůže ukládat tato data do svých sloupců. I kdyby tomu tak bylo, spuštění tak velkého vyhledávání bude trvat nepřijatelně dlouho.
Fulltextový vyhledávač je schopen spustit vyhledávací dotaz na milionech souborů najednou. Rychlost, jakou jsou data v dnešní době ukládána do aplikace, je obrovská. Spuštění fulltextového vyhledávání na tomto druhu objemu dat je obtížný úkol. Je to proto, že informace, které potřebujeme, mohou existovat v jediném souboru z miliard souborů uchovávaných na webu.
Jak Lucene funguje?
Zjevná otázka, která by vás měla napadnout, je, jak je Lucene tak rychlý při spouštění fulltextových vyhledávacích dotazů? Odpověď na to samozřejmě je pomocí indexů, které vytváří. Ale místo toho, aby vytvořil klasický index, Lucene využívá Invertované indexy.
V klasickém rejstříku shromažďujeme pro každý dokument úplný seznam slov nebo výrazů, které dokument obsahuje. V obráceném rejstříku u každého slova ve všech dokumentech ukládáme, jaký dokument a umístění tohoto slova / výrazu najdete na. Jedná se o vysoce standardní algoritmus, díky kterému je vyhledávání velmi snadné. Zvažte následující příklad vytvoření klasického indexu:
Doc1 -> "This", "is", "simple", "Lucene", "sample", "classic", "inverted", "index"Doc2 -> "Spuštěno", "Elasticsearch", "Ubuntu", "Aktualizovat"
Doc3 -> "RabbitMQ", "Lucene", "Kafka", "", "Spring", "Boot"
Pokud použijeme invertovaný index, budeme mít indexy jako:
This -> (2, 71)Lucene -> (1, 9), (12,87)
Apache -> (12, 91)
Rámec -> (32, 11)
Invertované indexy se udržují mnohem snadněji. Předpokládejme, že pokud chceme najít Apache podle mých podmínek, budu mít přímé odpovědi s Invertovanými indexy, zatímco s klasickým vyhledáváním poběží na úplných dokumentech, které by nebylo možné spustit ve scénářích v reálném čase.
Lucene workflow
Než bude moci Lucene skutečně vyhledávat data, je třeba provést kroky. Podívejme se na tyto kroky, abychom lépe porozuměli:
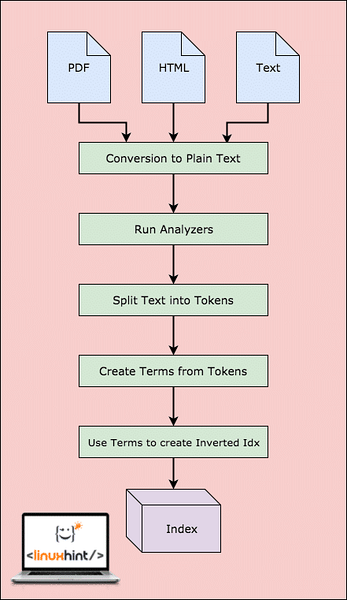
Lucene Workflow
Jak je znázorněno na obrázku, v Lucene se to děje:
- Lucene je napájen dokumenty a dalšími zdroji dat
- U každého dokumentu Lucene nejprve převede tato data na prostý text a poté analyzátory tento zdroj převede na prostý text
- Pro každý výraz v prostém textu se vytvoří obrácené indexy
- Indexy jsou připraveny k prohledání
Díky tomuto pracovnímu postupu je Lucene velmi silný fulltextový vyhledávač. Ale toto je jediná část, kterou Lucene splňuje. Musíme si tuto práci vykonat sami. Podívejme se na potřebné součásti indexování.
Lucene Components
V této části si popíšeme základní komponenty a základní třídy Lucene používané k vytváření indexů:
- Adresáře: Lucene index ukládá data do normálních adresářů systému souborů nebo do paměti, pokud potřebujete vyšší výkon. Je to zcela volba aplikací pro ukládání dat, kdekoli chce, databáze, paměti RAM nebo disku.
- Dokumenty: Data, která vkládáme do motoru Lucene, je třeba převést na prostý text. K tomu vytvoříme objekt Document, který představuje tento zdroj dat. Později, když spustíme vyhledávací dotaz, ve výsledku získáme seznam objektů dokumentu, které splňují dotaz, který jsme předali.
- Pole: Dokumenty jsou naplněny kolekcí polí. Pole je prostě pár (jméno, hodnota) položky. Při vytváření nového objektu dokumentu jej tedy musíme naplnit tímto druhem spárovaných dat. Když je pole inverzně indexováno, je hodnota pole tokenizována a je k dispozici pro vyhledávání. Nyní, když používáme Fields, není důležité ukládat skutečný pár, ale pouze převrácený indexovaný. Tímto způsobem můžeme rozhodnout, která data lze pouze prohledávat a není důležité je ukládat. Podívejme se na příklad zde:

Polní indexování
Ve výše uvedené tabulce jsme se rozhodli uložit některá pole a jiná nejsou uložena. Pole těla není uloženo, ale indexováno. To znamená, že e-mail bude vrácen jako výsledek při spuštění dotazu na jednu z podmínek pro obsah těla.
- Podmínky: Termíny představují slovo z textu. Termíny jsou tedy extrahovány z analýzy a tokenizace hodnot Fields Termín je nejmenší jednotka, na které je vyhledávání spuštěno.
- Analyzátory: Analyzátor je nejdůležitější součástí procesu indexování a vyhledávání. Je to Analyzer, který covertuje prostý text do Tokenů a Termínů, aby je bylo možné prohledávat. To není jediná zodpovědnost analyzátoru. Analyzer používá k výrobě tokenů Tokenizer. Analyzátor také provádí následující úkoly:
- Stemming: Analyzer převádí slovo na kmen. To znamená, že slovo „květiny“ se převede na kmenové slovo „květina“. Když se tedy spustí vyhledávání výrazu „květina“, dokument se vrátí.
- Filtrování: Analyzátor také filtruje stop slova jako „The“, „is“ atd. protože tato slova nepřitahují žádné dotazy ke spuštění a nejsou produktivní.
- Normalizace: Tento proces odstraní akcenty a další označení znaků.
To je běžná odpovědnost StandardAnalyzer.
Příklad aplikace
K vytvoření ukázkového projektu pro náš příklad použijeme jeden z mnoha Mavenových archetypů. Chcete-li vytvořit projekt, proveďte následující příkaz v adresáři, který budete používat jako pracovní prostor:
mvn archetyp: generate -DgroupId = com.linuxhint.příklad -DartifactId = LH-LuceneExample -DarchetypeArtifactId = maven-archetype-quickstart -DinteractiveMode = falsePokud používáte maven poprvé, bude trvat několik sekund, než se provede generování příkazu, protože maven musí stáhnout všechny požadované pluginy a artefakty, aby mohl generovat úlohu. Takto vypadá výstup projektu:
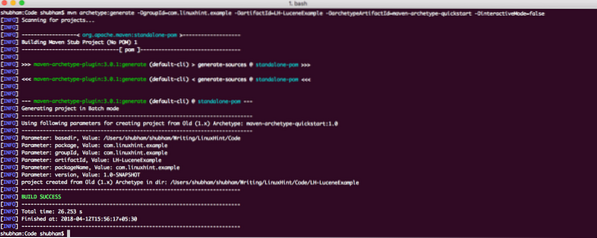
Nastavení projektu
Jakmile vytvoříte projekt, můžete jej otevřít ve svém oblíbeném IDE. Dalším krokem je přidání příslušných závislostí Maven do projektu. Tady je pom.xml soubor s příslušnými závislostmi:
Nakonec, abychom pochopili všechny JAR, které jsou přidány do projektu, když jsme přidali tuto závislost, můžeme spustit jednoduchý příkaz Maven, který nám umožní vidět kompletní strom závislostí pro projekt, když do něj přidáme některé závislosti. Zde je příkaz, který můžeme použít:
závislost mvn: stromKdyž spustíme tento příkaz, zobrazí se nám následující strom závislostí: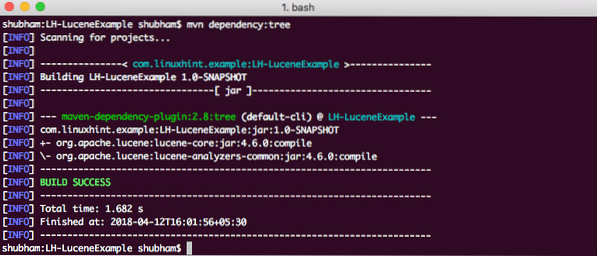
Nakonec vytvoříme třídu SimpleIndexer, která běží
importovat java.io.Soubor;
importovat java.io.FileReader;
importovat java.io.IOException;
import org.apache.Lucene.analýza.Analyzátor;
import org.apache.Lucene.analýza.Standard.StandardAnalyzer;
import org.apache.Lucene.dokument.Dokument;
import org.apache.Lucene.dokument.StoredField;
import org.apache.Lucene.dokument.Textové pole;
import org.apache.Lucene.index.IndexWriter;
import org.apache.Lucene.index.IndexWriterConfig;
import org.apache.Lucene.obchod.FSDirectory;
import org.apache.Lucene.util.Verze;
veřejná třída SimpleIndexer
private static final String indexDirectory = "/ Uživatelé / shubham / někde / LH-LuceneExample / Index";
private static final String dirToBeIndexed = "/ Users / shubham / někde / LH-LuceneExample / src / main / java / com / linuxhint / příklad";
public static void main (String [] args) vyvolá výjimku
File indexDir = nový soubor (indexDirectory);
Soubor dataDir = nový soubor (dirToBeIndexed);
SimpleIndexer indexer = nový SimpleIndexer ();
int numIndexed = indexátor.index (indexDir, dataDir);
Systém.ven.println ("Celkem indexovaných souborů" + numIndexed);
soukromý int index (File indexDir, File dataDir) vyvolá IOException
Analyzátor analyzátor = nový StandardAnalyzer (verze.LUCENE_46);
Konfigurace IndexWriterConfig = nový IndexWriterConfig (verze.LUCENE_46,
analyzátor);
IndexWriter indexWriter = nový IndexWriter (FSDirectory.otevřít (indexDir),
config);
Soubor [] soubory = dataDir.listFiles ();
pro (Soubor f: soubory)
Systém.ven.println ("Indexovací soubor" + f.getCanonicalPath ());
Dokument doc = nový dokument ();
doc.add (nový TextField ("obsah", nový FileReader (f)));
doc.add (new StoredField ("fileName", f.getCanonicalPath ()));
indexWriter.addDocument (doc);
int numIndexed = indexWriter.maxDoc ();
indexWriter.zavřít();
návrat numIndexed;
V tomto kódu jsme právě vytvořili instanci dokumentu a přidali nové pole, které představuje obsah souboru. Tady je výstup, který dostaneme, když spustíme tento soubor:
Indexovací soubor / Uživatelé / shubham / někde / LH-LuceneExample / src / main / java / com / linuxhint / příklad / SimpleIndexer.JávaCelkový počet indexovaných souborů 1
V projektu je také vytvořen nový adresář s následujícím obsahem:
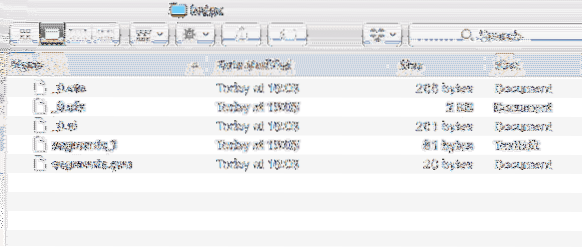
Indexová data
Budeme analyzovat, co jsou všechny soubory vytvořené v tomto rejstříku, v dalších lekcích pro Lucene.
Závěr
V této lekci jsme se podívali na to, jak Apache Lucene funguje, a také jsme vytvořili jednoduchý příklad aplikace založené na Maven a java.


