- Co je balíček Pandas
- Instalace a spuštění
- Načítání dat z CSV do Pandas DataFrame
- Co je DataFrame a jak to funguje
- Krájení datových rámců
- Matematické operace nad DataFrame
Vypadá to, že je toho hodně k pokrytí. Pojďme začít hned.
Co je balíček Python Pandas?
Podle domovské stránky Pandas: pandas je open source knihovna s licencí BSD poskytující vysoce výkonné a snadno použitelné datové struktury a nástroje pro analýzu dat pro programovací jazyk Python.
Jednou z nejlepších věcí na Pandas je to, že umožňuje čtení dat z běžných datových formátů, jako je CSV, SQL atd. velmi snadné, díky čemuž je stejně použitelné v produkčních aplikacích nebo jen v některých ukázkových aplikacích.
Nainstalujte Python Pandas
Jen poznámka před zahájením procesu instalace, pro tuto lekci používáme virtuální prostředí, které jsme vytvořili pomocí následujícího příkazu:
python -m virtualenv pandyzdrojové pandy / bin / aktivovat
Jakmile je virtuální prostředí aktivní, můžeme do virtuální env nainstalovat knihovnu pand, aby bylo možné provést příklady, které vytvoříme dále:
pip nainstalujte pandyNebo můžeme použít Conda k instalaci tohoto balíčku pomocí následujícího příkazu:
Conda nainstalovat pandyVidíme něco takového, když provedeme výše uvedený příkaz:
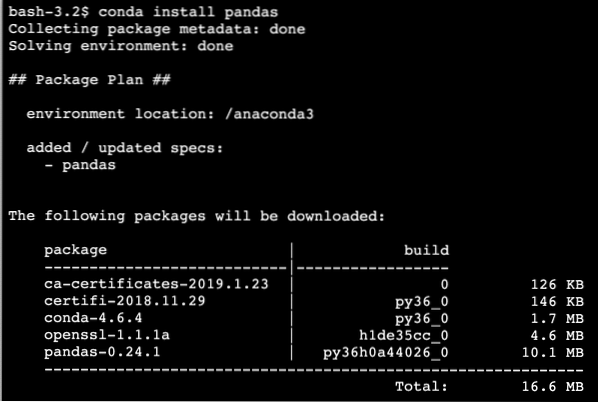
Jakmile se instalace dokončí pomocí Condy, budeme moci balíček použít v našich skriptech Pythonu jako:
importovat pandy jako pdZačněme nyní ve svých skriptech používat Pandy.
Čtení souboru CSV pomocí Pandas DataFrames
Čtení souboru CSV je s Pandas snadné. Pro demonstraci jsme zkonstruovali malý soubor CSV s následujícím obsahem:
Jméno, RollNo, datum přijetí, nouzový kontaktShubham, 1,20-05-2012,9988776655
Gagan, 2.20-05-2009, 8364517829
Oshima, 3,20-05-2003,5454223344
Vyom, 4,20-05-2009, 1223344556
Ankur, 5,20-05-1999,9988776655
Vinod, 6,20-05-1999,9988776655
Vipin, 7,20-05-2002,9988776655
Ronak, 8,20-05-2007, 1223344556
DJ, 9,20-05-2014,9988776655
VJ, 10,20-05-2015,9988776655
Uložte tento soubor do stejného adresáře jako skript Pythonu. Jakmile je soubor k dispozici, přidejte následující fragment kódu do souboru Pythonu:
importovat pandy jako pdstudenti = pd.read_csv ("studenti.csv ")
studenti.hlava()
Jakmile spustíme výše uvedený fragment kódu, uvidíme následující výstup:
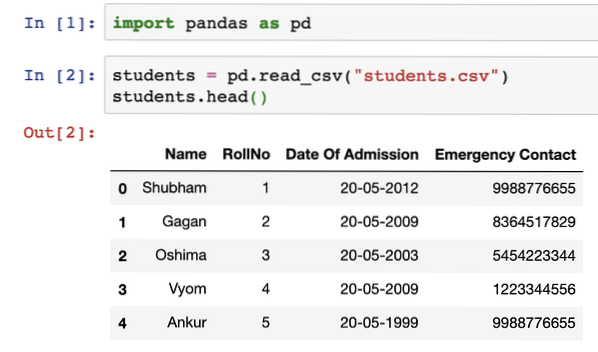
Funkce head () v Pandas lze použít k zobrazení vzorku dat přítomných v DataFrame. Počkejte, DataFrame? Budeme studovat mnohem více o DataFrame v další části, ale jen pochopíme, že DataFrame je n-dimenzionální datová struktura, kterou lze použít k uchovávání a analýze nebo komplexních operací nad sadou dat.
Můžeme také vidět, kolik řádků a sloupců mají aktuální data:
studenti.tvarJakmile spustíme výše uvedený fragment kódu, uvidíme následující výstup:

Pandy také počítají počet řádků od 0.
Je možné získat pouze sloupec v seznamu s Pandas. Toho lze dosáhnout pomocí indexování v Pandách. Podívejme se na krátký fragment kódu:
student_names = students ['Name']student_names
Jakmile spustíme výše uvedený fragment kódu, uvidíme následující výstup:
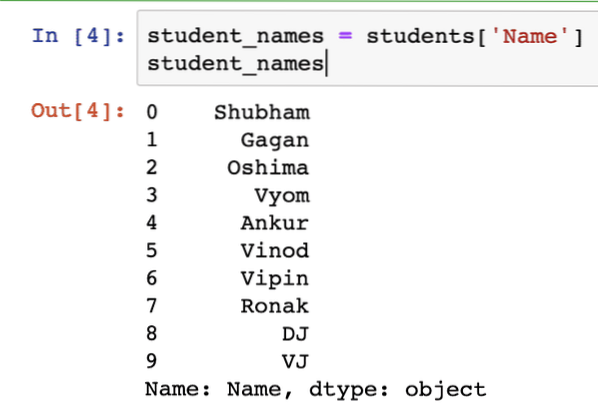
Ale to nevypadá jako seznam, že?? Musíme explicitně zavolat funkci pro převod tohoto objektu na seznam:
student_names = student_names.seznam ()student_names
Jakmile spustíme výše uvedený fragment kódu, uvidíme následující výstup:
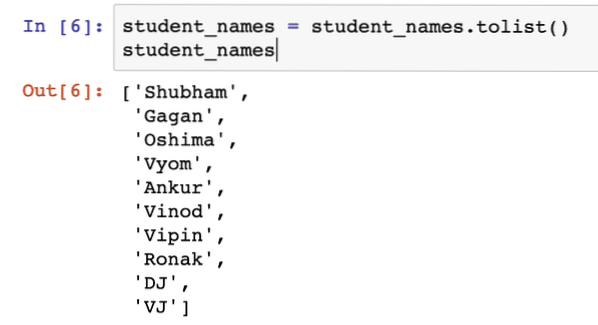
Jen pro další informace se můžeme ujistit, že každý prvek v seznamu je jedinečný a nevyprázdněné prvky vybereme pouze přidáním několika jednoduchých kontrol jako:
student_names = students ['Name'].dropna ().unikátní().seznam ()V našem případě se výstup nezmění, protože seznam již neobsahuje žádné chybné hodnoty.
Můžeme také vytvořit DataFrame se surovými daty a předat spolu s nimi názvy sloupců, jak je znázorněno v následujícím fragmentu kódu:
my_data = pd.DataFrame ([
[1, „Chan“],
[2, „Smith“],
[3, „Winslet“]
],
sloupce = ["Hodnocení", "Příjmení"]
)
moje_data
Jakmile spustíme výše uvedený fragment kódu, uvidíme následující výstup:

Krájení datových rámců
Rozdělení datových rámců pro extrakci pouze vybraných řádků a sloupců je důležitá funkce pro udržení pozornosti směrem k požadovaným částem dat, která potřebujeme použít. Za tímto účelem nám Pandas umožňuje rozdělit DataFrame podle potřeby pomocí příkazů jako:
- iloc [: 4 ,:] - vybere první 4 řádky a všechny sloupce pro tyto řádky.
- iloc [:,:] - je vybrán kompletní DataFrame
- iloc [5:, 5:] - řádky od pozice 5 a sloupce od pozice 5 a dále.
- iloc [:, 0] - první sloupec a všechny řádky sloupce.
- iloc [9 ,:] - 10. řádek a všechny sloupce pro tento řádek.
V předchozí části jsme již viděli indexování a krájení s názvy sloupců místo indexů. Je také možné kombinovat řezy s čísly indexů a názvy sloupců. Podívejme se na jednoduchý fragment kódu:
studenti.loc [: 5, 'Jméno']Jakmile spustíme výše uvedený fragment kódu, uvidíme následující výstup:

Je možné zadat více než jeden sloupec:
studenti.loc [: 5, ['Jméno', 'Tísňový kontakt']]]Jakmile spustíme výše uvedený fragment kódu, uvidíme následující výstup:
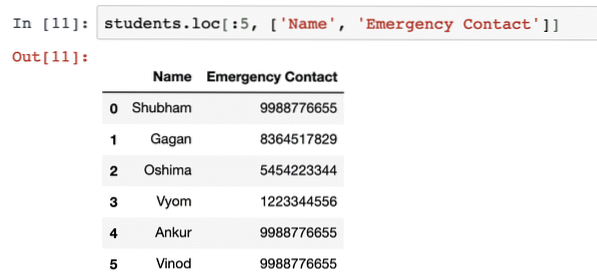
Sériová datová struktura v pandách
Stejně jako Pandas (což je vícerozměrná datová struktura), je Series jednorozměrná datová struktura v Pandas. Když načteme jeden sloupec z DataFrame, ve skutečnosti pracujeme s Series: When we retrieve a single column from a DataFrame, we we actually working with a Series:
typ (studenti ["jméno"])Jakmile spustíme výše uvedený fragment kódu, uvidíme následující výstup:
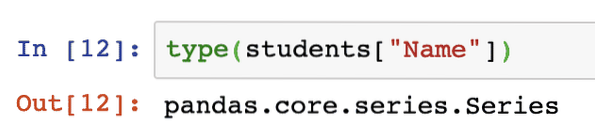
Můžeme také postavit vlastní sérii, zde je fragment kódu pro stejné:
série = pd.Seriál (['Shubham', 3.7])série
Jakmile spustíme výše uvedený fragment kódu, uvidíme následující výstup:

Jak je zřejmé z výše uvedeného příkladu, Series může obsahovat také více datových typů pro stejný sloupec.
Booleovské filtry v Pandas DataFrame
Jednou z dobrých věcí v Pandas je, jak je možné extrahovat data z DataFrame na základě podmínky. Stejně jako extrahování studentů pouze v případě, že počet rolí je větší než 6:
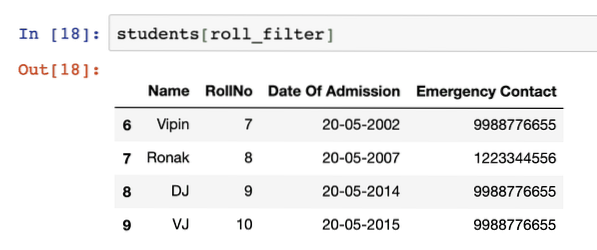
roll_filter = students ['RollNo']> 6roll_filter
Jakmile spustíme výše uvedený fragment kódu, uvidíme následující výstup:
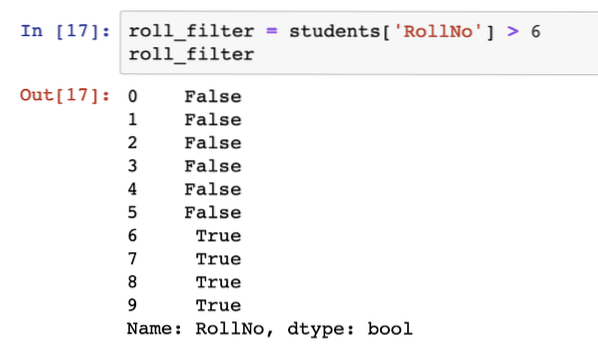
To není to, co jsme očekávali. I když je výstup zcela explicitní o tom, které řádky uspokojily filtr, který jsme poskytli, ale stále nemáme přesné řádky, které tento filtr uspokojily. Ukázalo se, že můžeme použít filtry jako indexy DataFrame také:
studenti [roll_filter]Jakmile spustíme výše uvedený fragment kódu, uvidíme následující výstup:
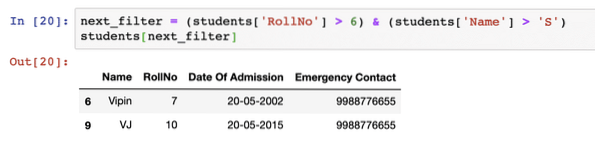
Ve filtru je možné použít více podmínek, aby bylo možné data filtrovat na jeden výstižný filtr, například:
next_filter = (studenti ['RollNo']> 6) & (studenti ['Name']> 'S')studenti [next_filter]
Jakmile spustíme výše uvedený fragment kódu, uvidíme následující výstup:
Výpočet mediánu
V DataFrame můžeme vypočítat také mnoho matematických funkcí. Uvedeme dobrý příklad výpočtu mediánu. Medián se vypočítá pro datum, nikoli pouze pro čísla. Podívejme se na krátký fragment kódu:
data = studenti ['datum přijetí'].astype ('datetime64 [ns]').kvantil (.5)Termíny
Jakmile spustíme výše uvedený fragment kódu, uvidíme následující výstup:

Dosáhli jsme toho nejprve indexováním sloupce data, který máme, a poté poskytnutím datového typu sloupci, aby jej Pandas mohl správně odvodit, když použije kvantilovou funkci k výpočtu mediánu data.
Závěr
V této lekci jsme se podívali na různé aspekty knihovny zpracování Pandas, které můžeme pomocí Pythonu použít ke shromažďování dat z různých zdrojů do datové struktury DataFrame, která nám umožňuje sofistikovaně pracovat s datovou sadou. Umožňuje nám také získat podmnožinu dat, na kterých chceme momentálně pracovat, a poskytuje mnoho matematických operací.
Sdělte nám svůj názor na lekci na Twitteru s @sbmaggarwal a @LinuxHint.