pip nainstalujte BeautifulSoup4
Chcete-li zkontrolovat, zda byla instalace úspěšná, aktivujte interaktivní prostředí Pythonu a importujte BeautifulSoup. Pokud se nezobrazí žádná chyba, znamená to, že vše proběhlo v pořádku. Pokud nevíte, jak na to, zadejte do terminálu následující příkazy.
$ pythonPython 3.5.2 (výchozí, 14. září 2017, 22:51:06)
[GCC 5.4.0 20160609] na Linuxu
Další informace získáte zadáním „help“, „copyright“, „credit“ nebo „license“.
>>> import bs4
Abyste mohli pracovat s knihovnou BeautifulSoup, musíte předat html. Při práci se skutečnými webovými stránkami můžete získat html webové stránky pomocí knihovny požadavků. Instalace a použití knihovny požadavků přesahuje rámec tohoto článku, ale v dokumentaci byste se dobře orientovali, její použití je celkem snadné. V tomto článku jednoduše použijeme html v řetězci pythonu, který bychom volali html.
html = "" "[chráněno e-mailem]
pparkerworks.com
„“ „
Chcete-li použít beautifulsoup, importujeme jej do kódu pomocí níže uvedeného kódu:
z importu bs4 BeautifulSoupTo by představilo BeautifulSoup do našeho jmenného prostoru a můžeme ho použít při analýze našeho řetězce.
soup = BeautifulSoup (html, "lxml")Nyní, polévka je objekt BeautifulSoup typu bs4.BeautifulSoup a můžeme provádět všechny operace BeautifulSoup na internetu polévkaproměnná.
Pojďme se nyní podívat na některé věci, které můžeme s BeautifulSoup dělat.
DĚLAT Ošklivé, KRÁSNÉ
Když BeautifulSoup analyzuje html, není to obvykle v nejlepším formátu. Rozteč je docela hrozná. Značky je těžké najít. Zde je obrázek, který ukazuje, jak by vypadaly, když vytisknete soubor polévka:
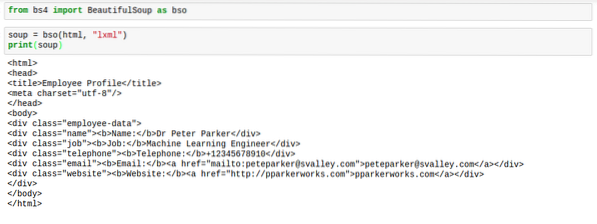
Existuje však řešení tohoto problému. Řešení dává html perfektní rozestup, díky čemuž věci vypadají dobře. Toto řešení se zaslouženě nazývá „předstírat".
Je pravda, že tuto funkci nebudete moci používat většinu času; jsou však chvíle, kdy nemusíte mít přístup k nástroji pro kontrolu prvků ve webovém prohlížeči. V době omezených zdrojů byste považovali metodu prettify za velmi užitečnou.
Jak to používáte:
polévka.prettify ()Značka by vypadala správně rozmístěná, stejně jako na obrázku níže:
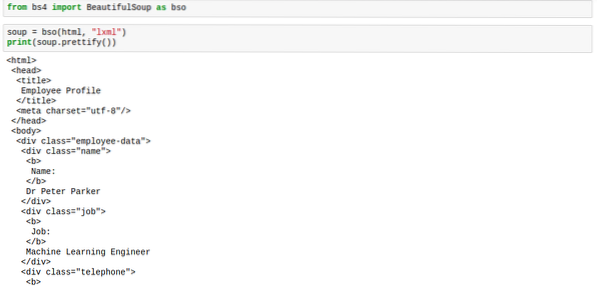
Když na polévku použijete metodu prettify, výsledkem již nebude typ bs4.Krásná polévka. Výsledkem je nyní typ 'unicode'. To znamená, že na něj nelze použít jiné metody BeautifulSoup, nicméně polévka samotná není ovlivněna, takže jsme v bezpečí.
NAJDETE NAŠE OBLÍBENÉ ZNAČKY
HTML se skládá ze značek. Ukládá do nich všechna svá data a uprostřed toho nepořádku leží data, která potřebujeme. V zásadě to znamená, že když najdeme správné značky, můžeme získat to, co potřebujeme.
Jak tedy najdeme správné značky? Využíváme metody BeautifulSoup find a find_all.
Fungují takto:
The nalézt metoda vyhledá první značku s potřebným názvem a vrátí objekt typu bs4.živel.Štítek.
The najít_všechno metoda na druhé straně vyhledá všechny tagy s potřebným názvem tagu a vrátí je jako seznam typu bs4.živel.ResultSet. Všechny položky v seznamu jsou typu bs4.živel.Označte, abychom mohli provést indexování v seznamu a pokračovat v průzkumu naší krásné skupiny.
Podívejme se na nějaký kód. Najdeme všechny značky div:
polévka.najít („div“)Získali bychom následující výsledek:
Při kontrole proměnné html byste si všimli, že se jedná o první značku div.
polévka.find_all („div“)Získali bychom následující výsledek:
[[chráněno e-mailem]
pparkerworks.com
Vrátí seznam. Pokud například chcete třetí značku div, spustíte následující kód:
polévka.find_all („div“) [2]Vrátilo by následující:
NAJDĚNÍ ATRIBUTŮ NAŠICH OBLÍBENÝCH ZNAČEK
Nyní, když jsme viděli, jak získat naše oblíbené značky, co takhle získat jejich atributy?
Možná si v tuto chvíli myslíte: „K čemu potřebujeme atributy?". Mnohokrát většina údajů, které potřebujeme, budou e-mailové adresy a webové stránky. Tento druh dat je obvykle hypertextový odkaz na webové stránky, s odkazy v atributu „href“.
Když jsme extrahovali potřebnou značku pomocí metod find nebo find_all, můžeme získat atributy aplikací attrs. To by vrátilo slovník atributu a jeho hodnoty.
Například pro získání atributu email dostaneme značky, které obklopují potřebné informace, a proveďte následující.
polévka.find_all („a“) [0].attrsKterý by vrátil následující výsledek:
'href': 'mailto: [chráněno e-mailem' 'Totéž pro atribut webu.
polévka.find_all („a“) [1].attrsKterý by vrátil následující výsledek:
'href': 'http: // pparkerworks.com'Vrácené hodnoty jsou slovníky a k získání klíčů a hodnot lze použít běžnou syntaxi slovníku.
Podívejme se na rodiče a děti
Všude jsou značky. Někdy chceme vědět, co jsou podřízené značky a co je nadřazená značka.
Pokud ještě nevíte, co je nadřazená a podřízená značka, mělo by stačit toto krátké vysvětlení: nadřazená značka je okamžitá vnější značka a dítě je okamžitá vnitřní značka dané značky.
Když se podíváme na náš html, tag body je nadřazený tag všech tagů div. Tučná značka a značka ukotvení jsou také podřízenými značkami div, kde je to vhodné, protože ne všechny značky div mají značky kotvy.
Takže můžeme získat přístup k nadřazené značce voláním findParent metoda.
polévka.najít („div“).findParent ()To by vrátilo celou značku těla:
[chráněno e-mailem]
pparkerworks.com
Chcete-li získat podřízenou značku čtvrté značky div, nazýváme najít děti metoda:
polévka.find_all ("div") [4].findChildren ()Vrátí následující:
[Webová stránka:, pparkerworks.com]Co pro nás obsahuje?
Při procházení webových stránek nevidíme značky všude na obrazovce. Vidíme pouze obsah různých značek. Co když chceme obsah značky, aniž by nám všechny hranaté závorky znepříjemňovaly život? To není těžké, vše, co bychom udělali, je zavolat get_text metoda na tagu dle výběru a dostaneme text do tagu a pokud tag má v sobě další tagy, získá také jejich textové hodnoty.
Zde je příklad:
polévka.najít („tělo“).get_text ()Tím se vrátí všechny textové hodnoty ve značce body:
Jméno: Dr. Peter ParkerPráce: Inženýr strojového učení
Telefon: +12345678910
E-mail: [chráněn e-mailem]
Webové stránky: pparkerworks.com
ZÁVĚR
To je to, co pro tento článek máme. S krásnou polévkou však lze udělat ještě další zajímavé věci. Můžete si prohlédnout dokumentaci nebo použít dir (BeautfulSoup) na interaktivním prostředí zobrazíte seznam operací, které lze s objektem BeautifulSoup provádět. To je ode mě dnes všechno, dokud znovu nenapíšu.


