Nalezení a výběr prvků z webové stránky je klíčem ke škrábání webu se selenem. K vyhledání a výběru prvků z webové stránky můžete použít selektor XPath v selenu.
V tomto článku vám ukážu, jak vyhledávat a vybírat prvky z webových stránek pomocí selektorů XPath v selenu pomocí knihovny pythonů selenu. Pojďme tedy začít.
Předpoklady:
Chcete-li vyzkoušet příkazy a příklady tohoto článku, musíte mít,
- Ve vašem počítači nainstalovaná distribuce Linuxu (nejlépe Ubuntu).
- Python 3 nainstalovaný ve vašem počítači.
- PIP 3 nainstalovaný ve vašem počítači.
- Krajta virtuální balíček nainstalovaný v počítači.
- Ve vašem počítači jsou nainstalovány webové prohlížeče Mozilla Firefox nebo Google Chrome.
- Musíte vědět, jak nainstalovat ovladač Firefox Gecko nebo webový ovladač Chrome.
Pro splnění požadavků 4, 5 a 6 si přečtěte můj článek Úvod do selenu v Pythonu 3. Na LinuxHint najdete mnoho článků o dalších tématech.com. Nezapomeňte je zkontrolovat, pokud potřebujete pomoc.
Nastavení adresáře projektu:
Chcete-li mít vše uspořádané, vytvořte nový adresář projektu selen-xpath / jak následuje:
$ mkdir -pv selenium-xpath / ovladače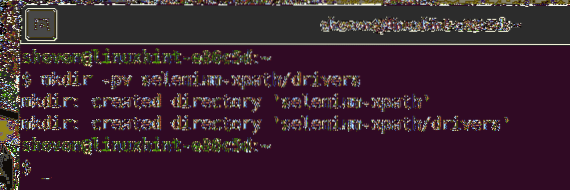
Přejděte na selen-xpath / adresář projektu takto:
$ cd selenium-xpath /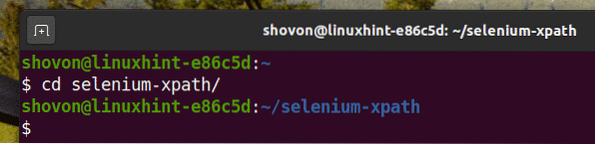
Vytvořte virtuální prostředí Pythonu v adresáři projektu následujícím způsobem:
$ virtualenv .venv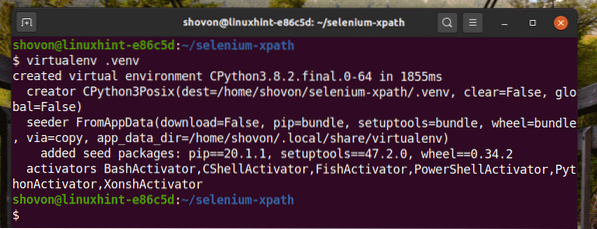
Aktivujte virtuální prostředí následujícím způsobem:
$ zdroj .venv / bin / aktivovat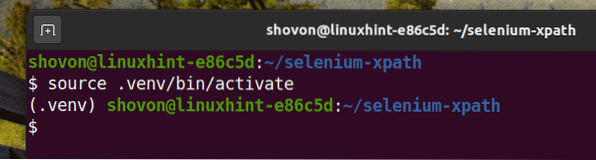
Nainstalujte knihovnu Selenium Python pomocí PIP3 následujícím způsobem:
$ pip3 nainstalujte selen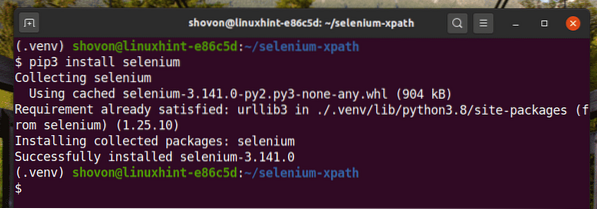
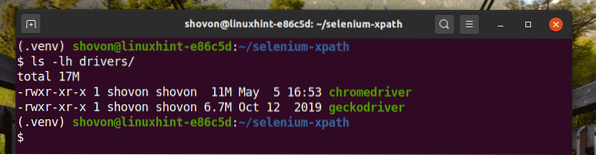
Stáhněte a nainstalujte všechny požadované webové ovladače v Řidiči/ adresář projektu. Proces stahování a instalace webových ovladačů jsem vysvětlil ve svém článku Úvod do selenu v Pythonu 3.
Získejte nástroj XPath Selector pomocí nástroje pro vývojáře v prohlížeči Chrome:
V této části vám ukážu, jak najít selektor XPath prvku webové stránky, který chcete vybrat, pomocí selenu pomocí integrovaného vývojářského nástroje webového prohlížeče Google Chrome.
Chcete-li získat volič XPath pomocí webového prohlížeče Google Chrome, otevřete Google Chrome a navštivte web, ze kterého chcete extrahovat data. Poté stiskněte pravé tlačítko myši (RMB) na prázdné ploše stránky a klikněte na Kontrolovat otevřít Chrome Developer Tool.
Můžete také stisknout
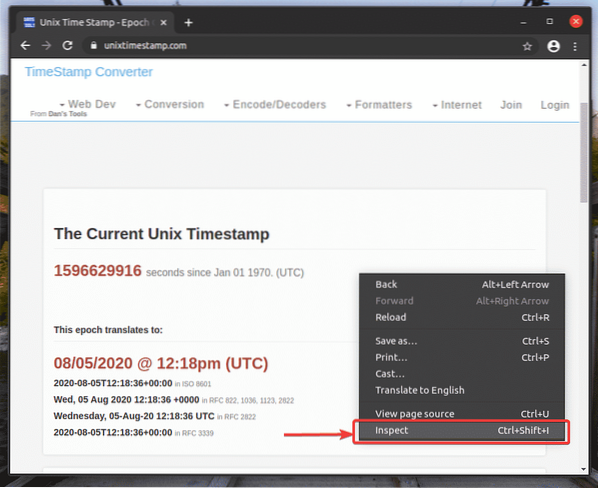
Chrome Developer Tool by měl být otevřen.
Chcete-li najít reprezentaci HTML požadovaného prvku webové stránky, klikněte na ikonu Kontrolovat(
ikona), jak je označeno na snímku obrazovky níže.
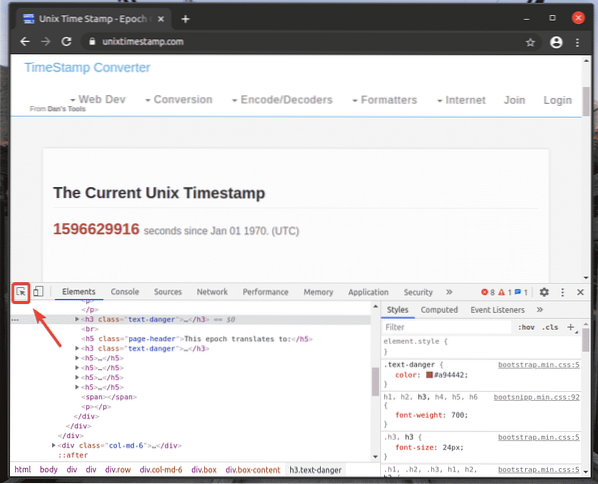
Poté umístěte kurzor na požadovaný prvek webové stránky a vyberte jej levým tlačítkem myši (LMB).
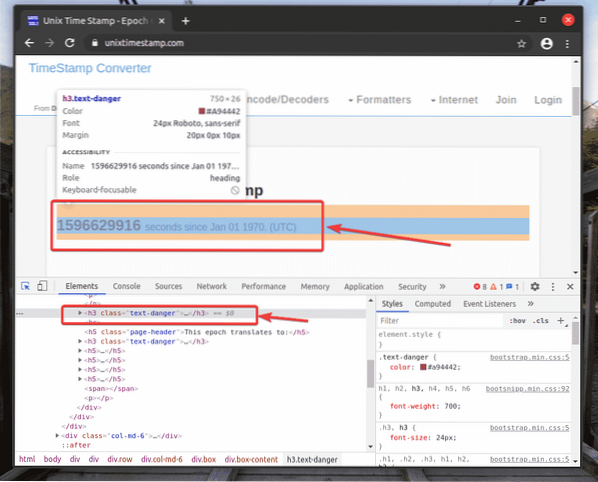
Reprezentace HTML vybraného webového prvku bude zvýrazněna v Elementy záložka Chrome Developer Tool, jak vidíte na snímku obrazovky níže.
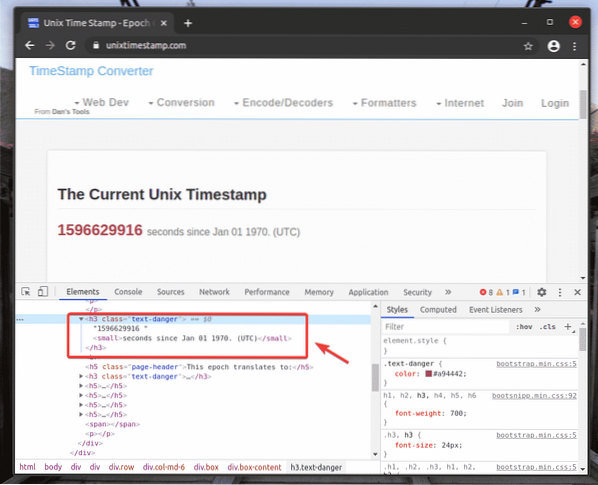
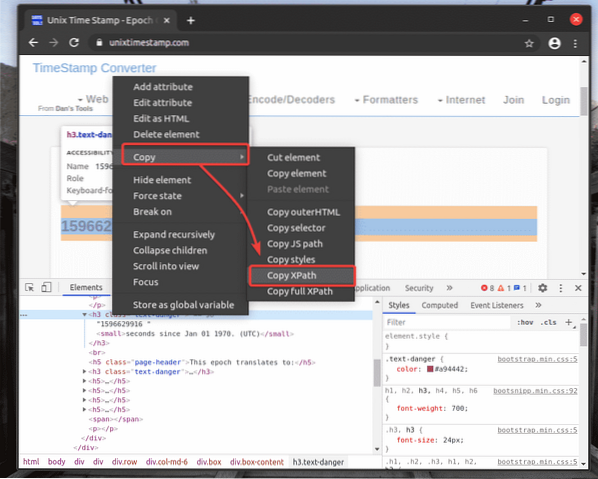
Chcete-li získat volič XPath požadovaného prvku, vyberte prvek z Elementy záložka Chrome Developer Tool a klikněte na něj pravým tlačítkem (RMB). Poté vyberte kopírovat > Zkopírujte XPath, jak je uvedeno na snímku obrazovky níže.
Vložil jsem volič XPath do textového editoru. Selektor XPath vypadá, jak je znázorněno na následujícím obrázku.

Získejte nástroj XPath Selector pomocí vývojového nástroje Firefox:
V této části vám ukážu, jak pomocí selenu najít volič XPath prvku webové stránky, který chcete vybrat, pomocí vestavěného vývojářského nástroje webového prohlížeče Mozilla Firefox.
Chcete-li získat volič XPath pomocí webového prohlížeče Firefox, otevřete Firefox a navštivte web, ze kterého chcete extrahovat data. Poté stiskněte pravé tlačítko myši (RMB) na prázdné ploše stránky a klikněte na Zkontrolovat prvek (Q) otevřít Nástroj pro vývojáře Firefoxu.
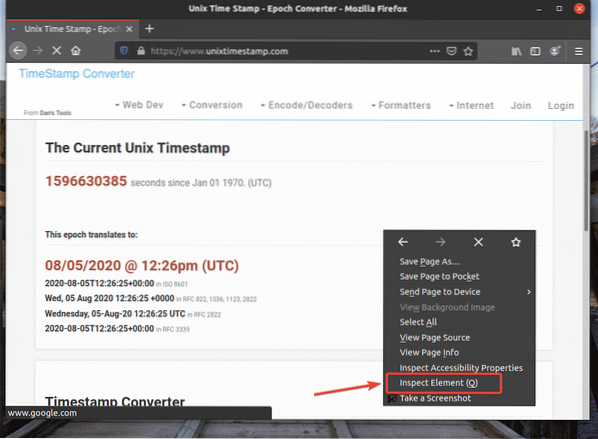
Nástroj pro vývojáře Firefoxu by měl být otevřen.
Chcete-li najít reprezentaci HTML požadovaného prvku webové stránky, klikněte na ikonu Kontrolovat(
ikona), jak je označeno na snímku obrazovky níže.
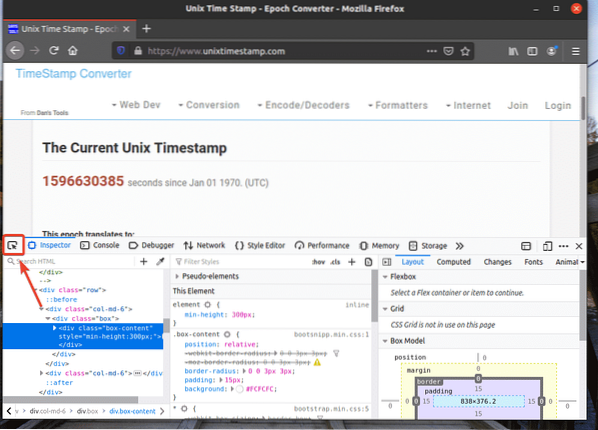
Poté umístěte kurzor na požadovaný prvek webové stránky a vyberte jej levým tlačítkem myši (LMB).
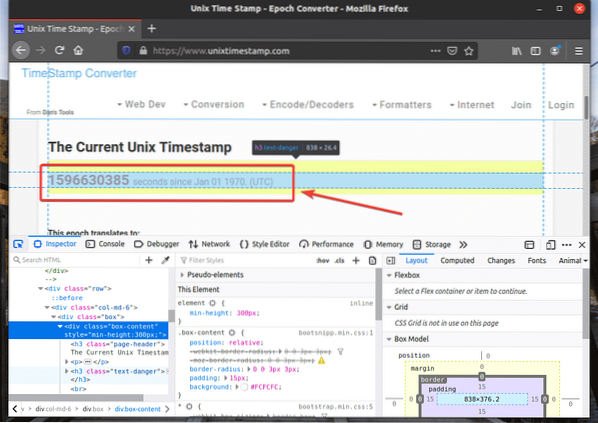
Reprezentace HTML vybraného webového prvku bude zvýrazněna v Inspektor záložka Nástroj pro vývojáře Firefoxu, jak vidíte na snímku obrazovky níže.
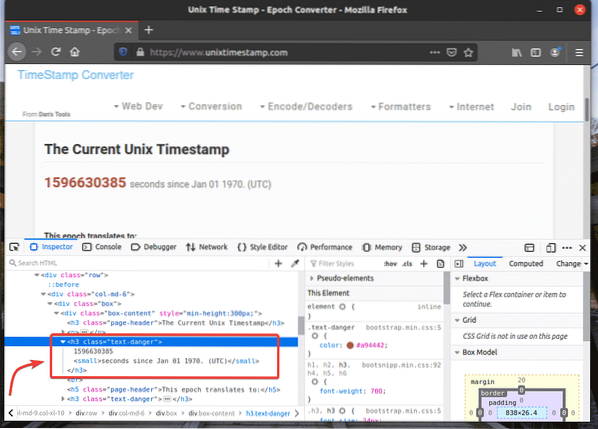
Chcete-li získat volič XPath požadovaného prvku, vyberte prvek z Inspektor záložka Nástroj pro vývojáře Firefoxu a klikněte na něj pravým tlačítkem (RMB). Poté vyberte kopírovat > XPath jak je uvedeno na snímku obrazovky níže.
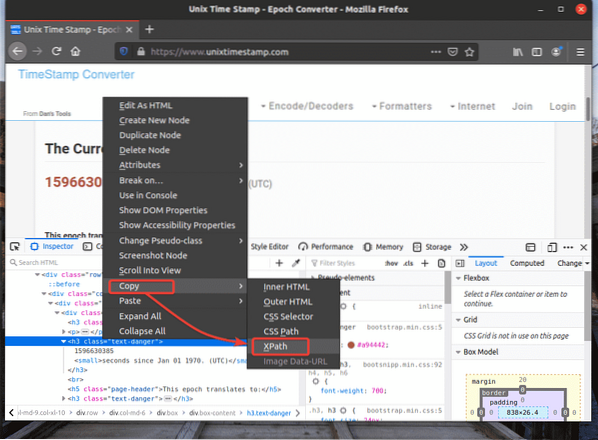
Selektor XPath požadovaného prvku by měl vypadat asi takto.

Extrakce dat z webových stránek pomocí nástroje XPath Selector:
V této části vám ukážu, jak vybrat prvky webové stránky a extrahovat z nich data pomocí selektorů XPath s knihovnou Selenium Python.
Nejprve vytvořte nový skript v Pythonu ex01.py a zadejte následující řádky kódů.
z webového ovladače pro import selenuze selenu.webdriver.běžný.klíče importovat klíče
ze selenu.webdriver.běžný.podle importu
options = webdriver.ChromeOptions ()
možnosti.bezhlavý = pravda
prohlížeč = webdriver.Chrome (executable_path = "./ ovladače / chromedriver ",
options = options)
prohlížeč.get ("https: // www.unixtimestamp.com / ")
timestamp = prohlížeč.find_element_by_xpath ('/ html / body / div [1] / div [1]
/ div [2] / div [1] / div / div / h3 [2] ')
print ('Aktuální časové razítko:% s'% (časové razítko.text.split (") [0]))
prohlížeč.zavřít()
Až budete hotovi, uložte ex01.py Skript v Pythonu.
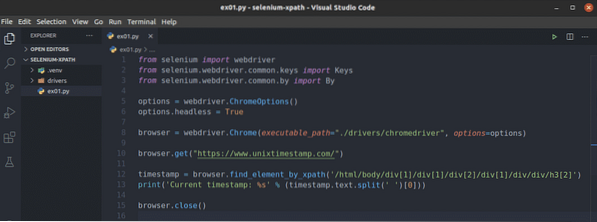
Řádek 1-3 importuje všechny požadované komponenty selenu.

Řádek 5 vytváří objekt Možnosti prohlížeče Chrome a řádek 6 umožňuje bezhlavý režim pro webový prohlížeč Chrome.

Řádek 8 vytváří Chrome prohlížeč objekt pomocí chromedriver binární z Řidiči/ adresář projektu.

Řádek 10 říká prohlížeči, aby načetl unixtimestamp webové stránky.com.

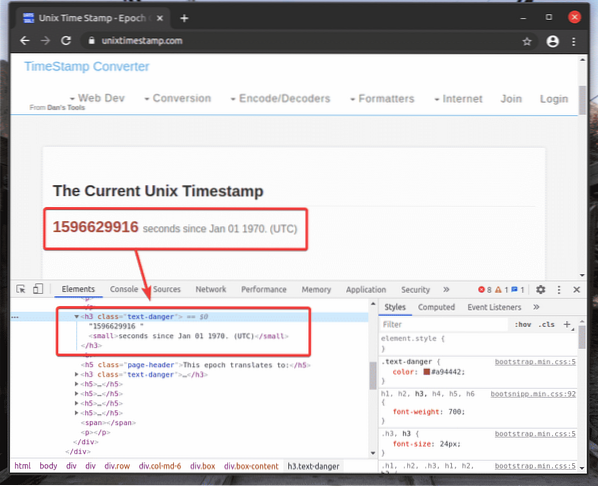
Řádek 12 najde prvek, který má data časového razítka ze stránky, pomocí voliče XPath a uloží jej do časové razítko proměnná.
Řádek 13 analyzuje data časových razítek z prvku a vytiskne je na konzole.

Zkopíroval jsem volič XPath označeného h2 prvek z unixtimestamp.com pomocí nástroje pro vývojáře Chrome.
Řádek 14 zavře prohlížeč.

Spusťte skript Pythonu ex01.py jak následuje:
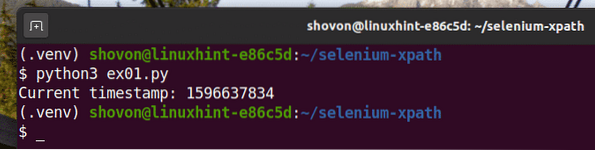
$ python3 ex01.py
Jak vidíte, data časového razítka se vytisknou na obrazovku.
Zde jsem použil prohlížeč.find_element_by_xpath (selektor) metoda. Jediným parametrem této metody je volič, což je selektor XPath prvku.
Namísto prohlížeč.find_element_by_xpath () metodu, můžete také použít prohlížeč.find_element (podle, selektor) metoda. Tato metoda vyžaduje dva parametry. První parametr Podle bude Podle.XPATH protože budeme používat selektor XPath a druhý parametr volič bude samotný selektor XPath. Výsledek bude stejný.
Chcete-li vidět jak prohlížeč.find_element () metoda funguje pro selektor XPath, vytvořte nový skript Pythonu ex02.py, zkopírujte a vložte všechny řádky z ex01.py na ex02.py a změnit řádek 12 jak je uvedeno na snímku obrazovky níže.
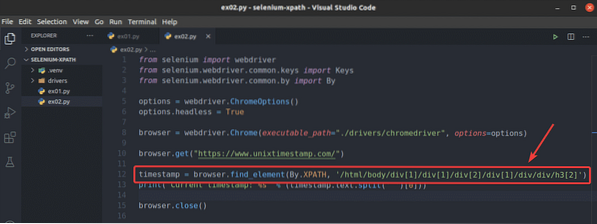
Jak vidíte, skript v Pythonu ex02.py dává stejný výsledek jako ex01.py.
$ python3 ex02.py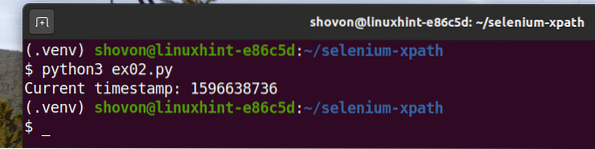
The prohlížeč.find_element_by_xpath () a prohlížeč.find_element () metody se používají k vyhledání a výběru jediného prvku z webových stránek. Pokud chcete najít a vybrat více prvků pomocí selektorů XPath, musíte použít prohlížeč.find_elements_by_xpath () nebo prohlížeč.find_elements () metody.
The prohlížeč.find_elements_by_xpath () metoda má stejný argument jako prohlížeč.find_element_by_xpath () metoda.
The prohlížeč.find_elements () metoda bere stejné argumenty jako prohlížeč.find_element () metoda.
Podívejme se na příklad extrakce seznamu jmen pomocí selektoru XPath generátor náhodných jmen.informace s knihovnou Selenium Python.
Neuspořádaný seznam (ol tag) má 10 li značky uvnitř každého obsahující náhodné jméno. XPath vyberte všechny li značky uvnitř ol značka v tomto případě je // * [@ id = ”main”] / div [3] / div [2] / ol // li
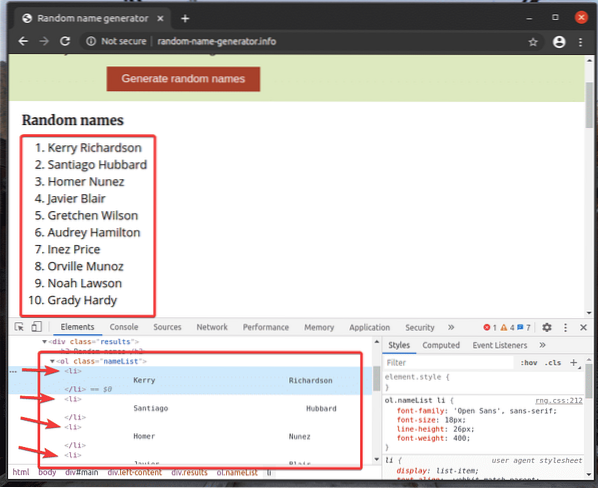
Pojďme si projít příkladem výběru více prvků z webové stránky pomocí selektorů XPath.
Vytvořte nový skript v Pythonu ex03.py a zadejte do něj následující řádky kódů.
z webového ovladače pro import selenuze selenu.webdriver.běžný.klíče importovat klíče
ze selenu.webdriver.běžný.podle importu
options = webdriver.ChromeOptions ()
možnosti.bezhlavý = pravda
prohlížeč = webdriver.Chrome (executable_path = "./ ovladače / chromedriver ",
options = options)
prohlížeč.get ("http: // generátor náhodných jmen.informace / ")
names = prohlížeč.find_elements_by_xpath ('
// * [@ id = "main"] / div [3] / div [2] / ol // li ')
pro jméno v jménech:
tisk (jméno.text)
prohlížeč.zavřít()
Až budete hotovi, uložte ex03.py Skript v Pythonu.
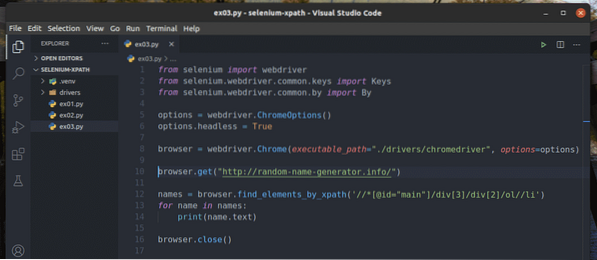
Řádek 1-8 je stejný jako v ex01.py Skript v Pythonu. Takže je zde nebudu znovu vysvětlovat.
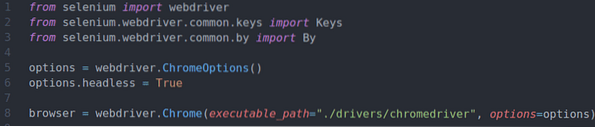
Řádek 10 říká prohlížeči, aby načetl generátor náhodných jmen webových stránek.informace.

Řádek 12 vybírá seznam jmen pomocí prohlížeč.find_elements_by_xpath () metoda. Tato metoda používá volič XPath // * [@ id = ”main”] / div [3] / div [2] / ol // li vyhledejte seznam jmen. Poté se seznam jmen uloží do složky jména proměnná.

V řádcích 13 a 14, a pro smyčka se používá k iteraci přes jména seznam a tisk názvů na konzole.
Řádek 16 zavře prohlížeč.

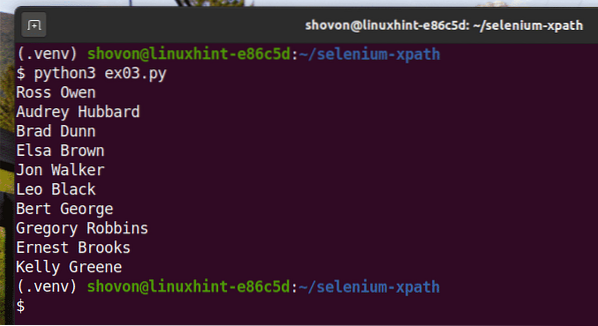
Spusťte skript Pythonu ex03.py jak následuje:
$ python3 ex03.py
Jak vidíte, jména jsou extrahována z webové stránky a vytištěna na konzole.
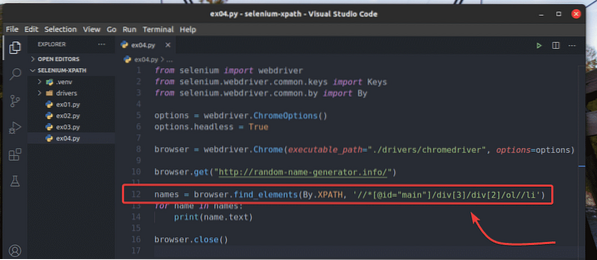
Místo použití prohlížeč.find_elements_by_xpath () metoda, můžete také použít prohlížeč.find_elements () metoda jako dříve. První argument této metody je Podle.XPATH, a druhým argumentem je selektor XPath.
Experimentovat s prohlížeč.find_elements () metoda, vytvořte nový skript Pythonu ex04.py, zkopírujte všechny kódy z ex03.py na ex04.py, a změňte řádek 12, jak je vyznačeno na následujícím obrázku.
Měli byste získat stejný výsledek jako předtím.
$ python3 ex04.py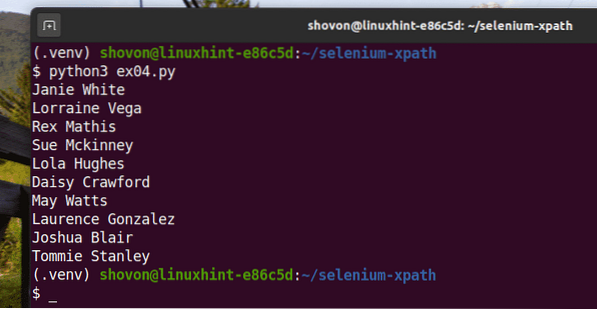
Základy výběru XPath:
Vývojový nástroj prohlížeče Firefox nebo webového prohlížeče Google Chrome generuje selektor XPath automaticky. Ale tyto selektory XPath někdy pro váš projekt nestačí. V takovém případě musíte vědět, co určitý selektor XPath dělá pro sestavení selektoru XPath. V této části vám ukážu základy selektorů XPath. Pak byste měli být schopni sestavit vlastní selektor XPath.
Vytvořte nový adresář www / v adresáři projektu takto:
$ mkdir -v www
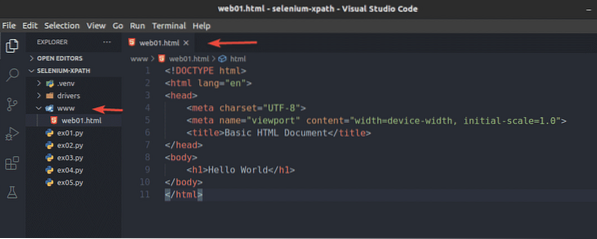
Vytvořte nový soubor web01.html v www / adresář a zadejte následující řádky v tomto souboru.
Ahoj světe
Až budete hotovi, uložte web01.html soubor.
Spusťte jednoduchý server HTTP na portu 8080 pomocí následujícího příkazu:
$ python3 -m http.server - adresář www / 8080
Server HTTP by se měl spustit.
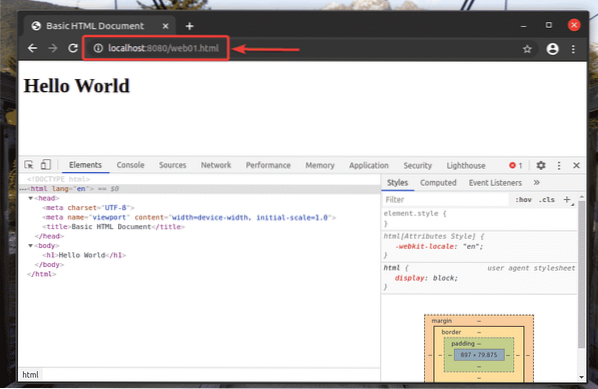
Měli byste mít přístup k web01.html soubor pomocí adresy URL http: // localhost: 8080 / web01.html, jak vidíte na obrázku níže.
Když je otevřený Firefox nebo Chrome Developer Tool, stiskněte
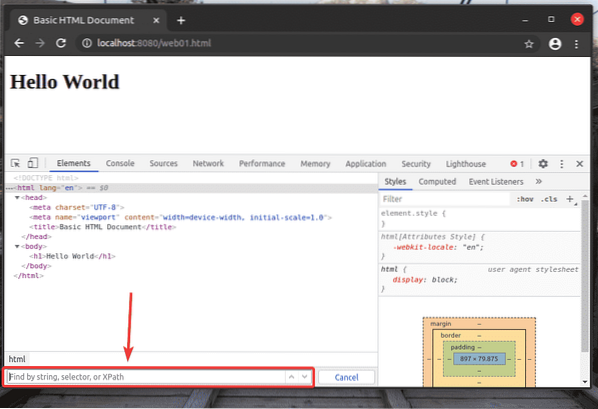
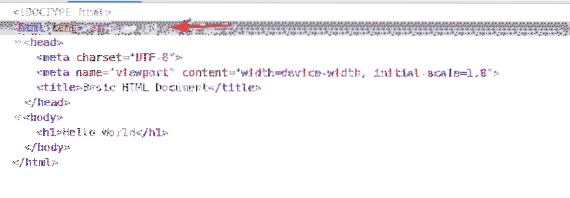
Selektor XPath začíná na lomítko (/) většinu času. Je to jako adresářový strom Linuxu. The / je kořenem všech prvků na webové stránce.
Prvním prvkem je html. Selektor XPath / html vybere celý html štítek.
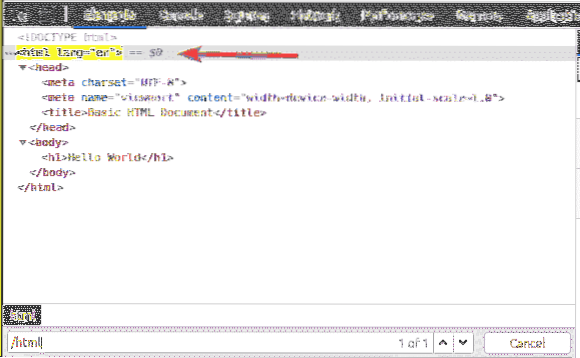
Uvnitř html tag, máme tělo štítek. The tělo tag lze vybrat pomocí selektoru XPath / html / tělo
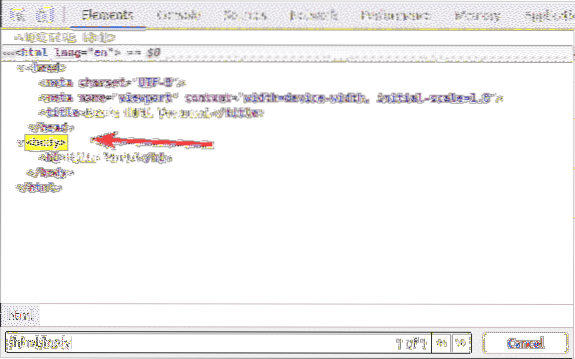
The h1 záhlaví je uvnitř tělo štítek. The h1 záhlaví lze vybrat pomocí selektoru XPath / html / body / h1
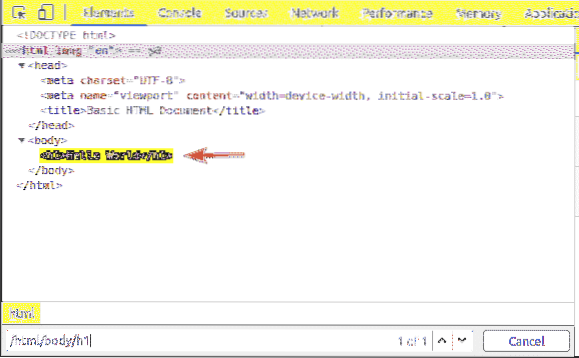
Tento typ selektoru XPath se nazývá selektor absolutní cesty. V selektoru absolutní cesty musíte procházet webovou stránku z kořene (/) stránky. Nevýhodou voliče absolutní cesty je, že i nepatrná změna ve struktuře webové stránky může váš selektor XPath zneplatnit. Řešením tohoto problému je relativní nebo částečný selektor XPath.
Chcete-li zjistit, jak relativní cesta nebo částečná cesta funguje, vytvořte nový soubor web02.html v www / adresář a zadejte do něj následující řádky kódů.
Ahoj světe
toto je zpráva
Ahoj světe
Až budete hotovi, uložte web02.html soubor a načtěte jej do svého webového prohlížeče.
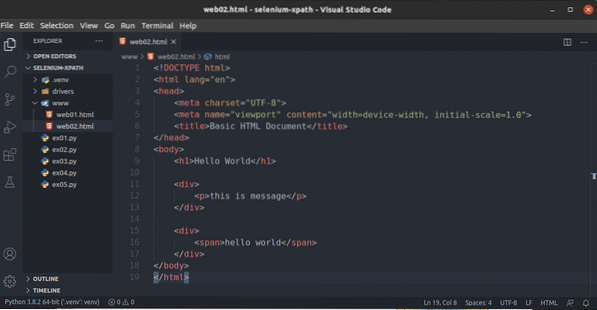
Jak vidíte, volič XPath // div / str vybere p značka uvnitř div štítek. Toto je příklad relativního selektoru XPath.
Relativní volič XPath začíná na //. Poté určíte strukturu prvku, který chcete vybrat. V tomto případě, div / str.
Tak, // div / str znamená vybrat p prvek uvnitř a div prvek, nezáleží na tom, co před ním bude.
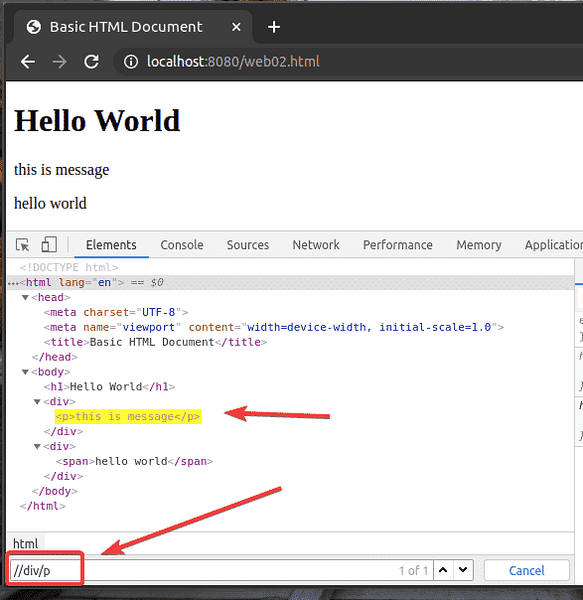
Můžete také vybrat prvky podle různých atributů, jako je id, třída, typ, atd. pomocí selektoru XPath. Uvidíme, jak to udělat.
Vytvořte nový soubor web03.html v www / adresář a zadejte do něj následující řádky kódů.
Ahoj světe
toto je zpráva
toto je další zpráva
nadpis 2
Lorem ipsum dolor sit amet consectetur, adipisicing elit. Quibusdam
accendendi doloribus sapiente, molestias quos quae non nam incidunt quis delectus
Facilis magni officiis alias neque atque fuga? Unde, aut natus?
Až budete hotovi, uložte web03.html soubor a načtěte jej do svého webového prohlížeče.
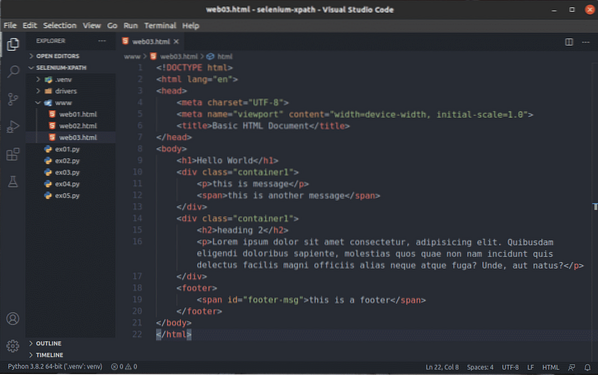
Řekněme, že chcete vybrat všechny div prvky, které mají třída název kontejner1. K tomu můžete použít selektor XPath // div [@ class = 'container1']
Jak vidíte, mám 2 prvky, které odpovídají voliči XPath // div [@ class = 'container1']
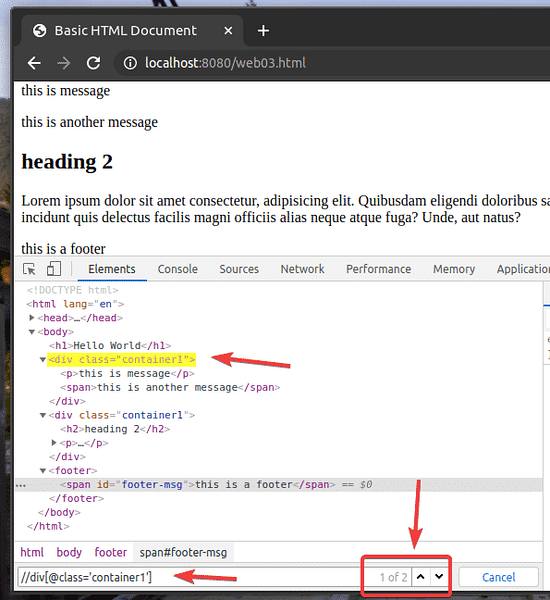
Chcete-li vybrat první div prvek s třída název kontejner1, přidat [1] na konci XPath vyberte, jak je znázorněno na následujícím obrázku.
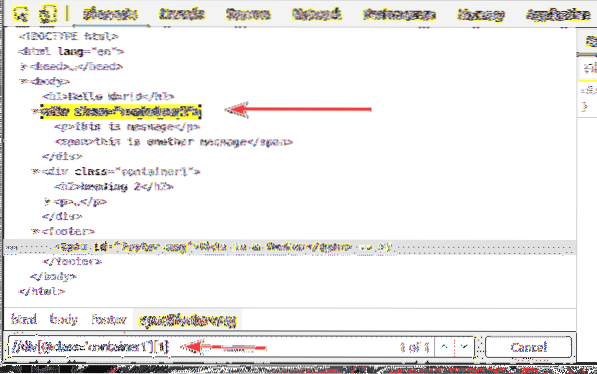
Stejným způsobem můžete vybrat druhý div prvek s třída název kontejner1 pomocí selektoru XPath // div [@ class = 'container1'] [2]
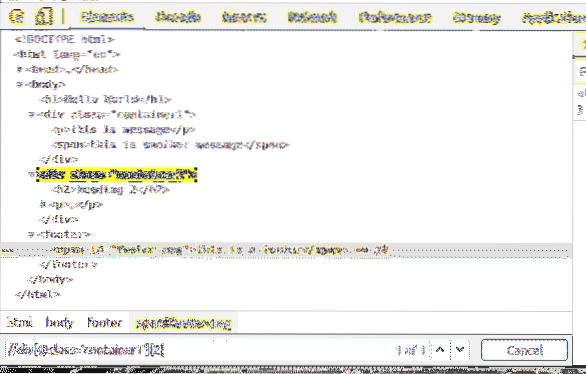
Prvky můžete vybrat pomocí id také.
Například pro výběr prvku, který má id z zápatí zprávy, můžete použít selektor XPath // * [@ id = 'footer-msg']
Tady * před [@ id = 'footer-msg'] se používá k výběru libovolného prvku bez ohledu na jeho značku.
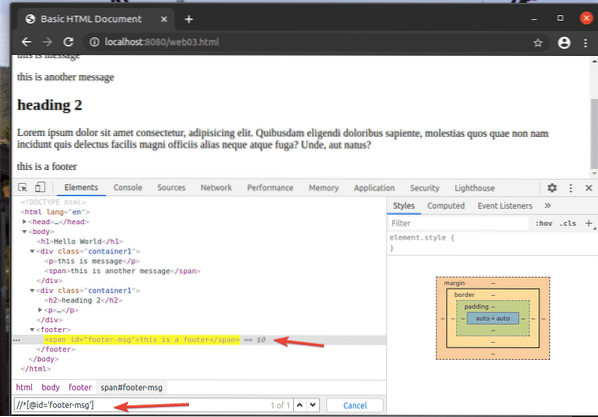
To jsou základy selektoru XPath. Nyní byste měli být schopni vytvořit vlastní selektor XPath pro vaše projekty selenu.
Závěr:
V tomto článku jsem vám ukázal, jak najít a vybrat prvky z webových stránek pomocí selektoru XPath s knihovnou Selenium Python. Také jsem diskutoval o nejběžnějších selektorech XPath. Po přečtení tohoto článku byste se měli cítit docela sebejistě při výběru prvků z webových stránek pomocí selektoru XPath s knihovnou Selenium Python.


