
Řetězec je jedním z nejpopulárnějších datových typů v pythonu. Můžeme použít datový typ řetězce k uložení jakýchkoli textových dat. V pythonu je jakýkoli znak v jednoduchých nebo dvojitých uvozovkách považován za řetězce. Tyto znaky mohou být kterékoli ze znaků Unicode, které podporují v pythonu. V tomto tutoriálu se naučíme téměř vše o datovém typu řetězce v pythonu.
Chcete-li postupovat podle tohoto tutoriálu, doporučujeme mít ve vašem systému nainstalovanou nejnovější verzi pythonu. Pokud máte ve svém systému nainstalovanou starší verzi pythonu, můžete postupovat podle našeho průvodce aktualizací pythonu v systému Linux.
Vytváření řetězců v Pythonu
Chcete-li vytvořit řetězec v pythonu, musíme dát pod znakům pole znaků. Python zachází s jednoduchými i dvojitými uvozovkami stejně, takže při vytváření řetězce můžeme použít kterýkoli z nich. Podívejte se na níže uvedené příklady, kde vytvoříme řetězec, uložíme je do proměnných a poté je vytiskneme.
# vytvoření řetězce
pozdrav = "Hello World"
# tisk řetězce
tisk (pozdrav)
Při spuštění výše uvedeného kódu získáte výstup Ahoj světe.

V tomto kódu jsme vytvořili řetězec Ahoj světea uložil jej do proměnné s názvem Pozdrav. Pak použijeme tiskovou funkci Python k zobrazení řetězce uloženého v proměnné. Po spuštění kódu získáte následující výstup. Můžeme také vytvořit víceřádkový řetězec pomocí trojitých uvozovek v níže uvedeném příkladu kódu.
var = "" "Lorem ipsum dolor sit amet,
consectetur adipiscing elit,
sed do eiusmod tempor incididunt
ut labore et dolore magna aliqua.„“ „
tisk (var)
Zde je výstup.

V Pythonu jsou řetězce pole bajtů představující znaky Unicode. Ale nemá žádný vestavěný datový typ pro jednotlivé znaky jako v C nebo C++. Jakýkoli řetězec, který má délku jednoho, je považován za znak.
Délka strun
V mnoha situacích možná budeme muset vypočítat nějakou délku řetězce. K dispozici je integrovaná funkce, která dokáže vypočítat délku řetězce. Funkce, kterou budeme používat, je len () funkce.
Chcete-li vidět praktický příklad len () funkce, spusťte ve svém prostředí Python IDE následující kód.
var = "Toto je řetězec"
print ("Délka řetězce je:", len (var))
Výstup:

Můžeme také použít python pro smyčku, o kterém jsem hovořil v tomto tutoriálu, k výpočtu délky řetězce.
Příklad:
var = "Toto je řetězec"
count = 0
pro i ve var:
count = count + 1
print ("Délka řetězce je:", počet)
Výstup:

Zřetězení řetězců
Zřetězení řetězců je sloučení nebo spojení dvou řetězců. Můžeme snadno spojit dva řetězce pomocí operátoru +. Podívejme se na příklad spojení dvou řetězců v pythonu.
# vytvoření dvou řetězců
string1 = "Dobrý den"
string2 = "Svět"
# sloučení dvou řetězců
pozdrav = řetězec1 + řetězec2
tisk (pozdrav)
Ve výše uvedeném kódu jsme vytvořili dva řetězce, jmenovitě „Hello“ a „World“, a ukládáme je do dvou proměnných s názvem řetězec1 a řetězec2. Potom jsme pomocí operátoru + spojili dva řetězce a uložili je do proměnné s názvem pozdrav a zobrazili ji pomocí tisk() funkce.
Výstup:

Opakování řetězce
Můžeme řetězec opakovat několikrát v pythonu pomocí operátoru *. Chcete-li například dvakrát vytisknout řetězec „Fosslinux“, musíme napsat následující kód.
tisk („Fosslinux“ * 2)
Výstup:

Formátování řetězců
Je snadné provádět formátování řetězců v Pythonu. Existují tři způsoby:
1. Starý styl formátování
Starý styl formátování řetězců se provádí pomocí operátoru%. Musíme použít speciální symboly jako „% s“, „% d“, „% f“, „%.F". pomocí řetězce a poté zadejte n-tici dat, která chceme na tomto místě formátovat. Podívejme se, jaká jsou data přijatá výše uvedenými symboly.
- % s: Přijme řetězce nebo jiná data s řetězcovou reprezentací, jako jsou čísla.
- % d:Používá se k datům celých čísel v řetězci.
- %F:Používá se pro čísla s plovoucí desetinnou čárkou.
- %.F: Používá se pro čísla s plovoucí desetinnou čárkou s pevnou přesností.
Například viz níže uvedený kód. Kód můžete zkopírovat a spustit ve vašem oblíbeném IDE pythonu.
string1 = "Je to formátovaný řetězec s celým číslem% d"% (1)
string2 = "Je to formátovaný řetězec s řetězcem% s"% ("Fosslinux")
string3 = "Je to formátovaný řetězec s floatovými daty% f"% (1.01)
tisk (řetězec1)
tisk (řetězec2)
tisk (string3)
Výstup:

Jak vidíme na výstupu, naformátovali jsme řetězce s daty celého čísla, floatu a řetězce. Tato metoda formátování řetězce je nejstarší způsob, ale v dnešní době se používá méně.
2. Použití metody format ()
Toto je nová technika formátování řetězců zavedená v Pythonu 3. Funkce format () berou data jako argument a nahrazují je v řetězci, kde je zástupný symbol jsou přítomni.
Příklad:
string1 = "Je to formátovaný řetězec s celým číslem ".formát (1)
string2 = "Je to formátovaný řetězec s řetězcem ".formát („Fosslinux“)
string3 = "Je to formátovaný řetězec s floatovými daty ".formát (1.01)
tisk (řetězec1)
tisk (řetězec2)
tisk (string3)
print („ je skvělý web pro učení a “.formát („FossLinux“, „Linux“, „Python“))
Získáme naformátovaný řetězec jako výstup při spuštění výše uvedeného kódu, jak je znázorněno na následujícím obrázku.

3. f-řetězce
Nejnovější technikou formátování řetězců je interpolace řetězců nebo f-řetězce, zavedené ve verzi 3 v Pythonu.6. Můžeme zadat název proměnné přímo v řetězci f a interpret jazyka Python nahradí název proměnné datovou hodnotou, která mu odpovídá. Řetězce f začínají písmenem f a data můžeme vkládat přímo do odpovídajících pozic. Tato technika formátování řetězců se v posledních dnech stala docela populární. Chcete-li zobrazit ukázku jeho fungování, zkopírujte níže uvedený kód a spusťte jej ve svém python IDE.
string1 = f "Je to formátovaný řetězec s celým číslem 1"
string2 = f "Je to formátovaný řetězec s řetězcem 'fosslinux'"
string3 = f "Je to formátovaný řetězec s plovoucími daty 0.01 "
tisk (řetězec1)
tisk (řetězec2)
tisk (string3)
a = "Fosslinux"
b = "Linux"
c = "Python"
print (f „a je skvělý web pro učení b a c“)
Pro formátování řetězců ve výše uvedeném kódu jsme použili metodu interpolace řetězců. Řetězce začínající znakem f jsou f-řetězce. Řetězec f nám usnadnil práci a můžeme proměnné zapisovat přímo do řetězců tak, že pod proměnné zadáme proměnné zástupný symbol. Při spuštění výše uvedeného kódu získáme následující výstup.

Zkontrolujte, zda není podřetězec
Často můžeme chtít zkontrolovat existenci postavy nebo podřetězec v řetězci. Toho lze dosáhnout pomocí v a ne v Klíčová slova Pythonu. Například zkontrolovat, zda Ahoj je v řetězci Ahoj světe, musíme spustit následující kód.
x = „ahoj“ v „ahoj světě“
tisk (x)
Při spuštění výše uvedeného kódu v IDE pythonu získáme booleovskou hodnotu Skutečný jako výstup, což znamená, že podřetězec „ahoj“ je přítomen ve „světě ahoj“.

Podívejte se na další ukázku, abyste věděli, jak to funguje lepším způsobem.
string = "FossLinux je skvělý web pro výuku Linuxu a Pythonu"
print ("Fosslinux" v řetězci)
print ("FossLinux" v řetězci)
tisk ("Foss" v řetězci)
print ("Pyt" v řetězci)
print ("hon" v řetězci)
print ("Python" není v řetězci)
Výstup:
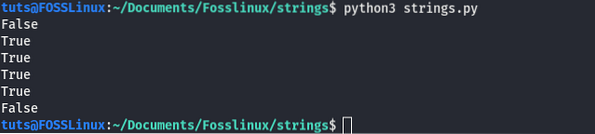
Ve výše uvedeném kódu jsme použili oba v a ne v klíčová slova ke kontrole podřetězce v nadřazeném řetězci.
Řetězec jako sled znaků
Řetězec pythonu je posloupnost znaků; jsou téměř podobné ostatním sekvencím seřazeným v pythonu, jako je list, n-tice atd. Můžeme extrahovat jednotlivé znaky z řetězců mnoha způsoby, jako je rozbalení pomocí proměnných a indexování, o kterých budu diskutovat v dalším tématu. Můžeme rozbalit řetězce tak, že je přiřadíme k proměnným. Chcete-li vidět, jak to funguje, stačí zkopírovat a spustit následující kód ve vašem oblíbeném IDE pythonu.
language = 'Fosslinux'
# rozbalení řetězce do proměnných
a, b, c, d, e, f, g, h, i = jazyk
tisk (a)
tisk (b)
tisk (c)
tisk (d)
tisk (e)
tisk (f)
tisk (g)
tisk (h)
tisk (i)
Výstup:
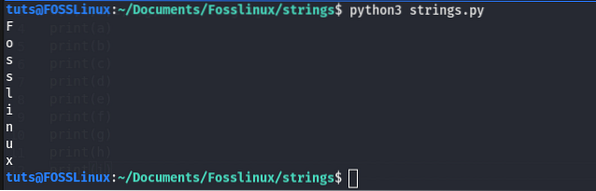
Indexovací řetězce
Indexování řetězců je základní a populární technika, pomocí které můžeme přistupovat k charakteru řetězce a velmi snadno provádět mnoho řetězcových operací. V programování začíná počítání nulou (0), takže pro získání prvního znaku řetězce musíme v indexu uvést nulu. Chcete-li vidět praktický příklad indexování, zkopírujte a spusťte následující kód v IDE Pythonu.
string = "Fosslinux"
tisk (řetězec [0])
tisk (řetězec [1])
tisk (řetězec [2])
tisk (řetězec [3])
Ve výše uvedeném kódu nejprve vytvoříme řetězec s názvem Fosslinux, a potom použijeme indexování řetězce pythonu k získání prvního, druhého, třetího a čtvrtého znaku řetězce. Po spuštění kódu dostaneme v terminálu následující výstup.

Python také podporuje negativní indexování, což je velmi užitečné tam, kde můžeme začít počítat z pravé strany. Například pro získání druhého posledního znaku řetězce „Fosslinux“ musíme napsat následující kód.
string = "Fosslinux"
print ("Druhý poslední člen řetězce je:", řetězec [-2])
Při spuštění kódu získáme druhý poslední termín řetězce „Fosslinux“, jak je znázorněno na následujícím obrázku.

Získání posledního termínu řetězce
Někdy můžeme chtít získat poslední člen řetězce. Máme dva způsoby, jak to udělat: první používá negativní indexování a druhý používá funkci len () s indexováním.
Chcete-li získat poslední člen řetězce pomocí negativního indexování, podívejte se na níže uvedený kód.
string = "Fosslinux"
print ("Poslední člen řetězce je:", řetězec [-1])
Výstup:

K získání posledního výrazu můžeme také použít funkci len () s indexováním. Abychom to mohli udělat, musíme vypočítat délku řetězce a potom musíme najít znak indexováním hodnoty, která je o jednu menší než délka řetězce. Viz níže uvedený příklad.
string = "Fosslinux"
délka = len (řetězec)
last_index = délka-1
print ("Poslední člen řetězce je:", řetězec [last_index])
Ve výše uvedeném kódu jsme nejprve vytvořili řetězec a uložili jej do proměnné s názvem tětiva. Poté vypočítáme délku řetězce pomocí metody len (). Protože indexování v pythonu začíná nulou, musíme odečíst jednu od délky. Pak jej předáme jako index do tětiva. Získáme tedy poslední znak řetězce.
Výstup:

Krájení strun
V Pythonu máme skvělou techniku, rozšířenou formu indexování, známou jako krájení řetězců. To lze použít k rozdělení řetězce na podřetězec. Chcete-li provést krájení, musíme v indexu řetězce uvést číslo indexu prvního znaku a posledního znaku podřetězce tak, že do nich vložíte středník. Praktické ukázky najdete v níže uvedeném příkladu kódu.
string = "Fosslinux"
tisk (řetězec [1: 6])
tisk (řetězec [0: 4])
Výstup:

Přeskakování znaků při krájení
Můžeme také přeskakovat znaky při krájení řetězce. Během krájení řetězce máme následující syntaxi.
řetězec [start: stop: step]
Start a stop jsou výchozí čísla indexů, která jsme dosud používali ve výše uvedené syntaxi. Parametr step přijímá celé číslo, které se používá k určení počtu znaků, které mají v každém kroku zůstat.
Reverzní struny
Řetězec můžeme snadno převrátit pomocí metody krájení. Například viz níže uvedený kód. Zkopírujte níže uvedený kód do svého IDE Pythonu a spusťte jej.
string = "Fosslinux"
print ("Reverzní řetězec", řetězec, "je", řetězec [:: - 1])
Tento kód obrátí řetězec „Fosslinux.„Po spuštění kódu získáme následující výstup.

Escape Character in Strings
Únikové znaky v programování jsou skvělým způsobem, jak do řetězců přidat netisknutelné znaky. Chcete-li například přidat nový znak řádku do řetězců, použijeme znak escape „\ n“. Demo najdete v níže uvedeném kódu.
print ("\ n \ n \ n Dobrý den \ n \ n Svět") Při spuštění kódu získáme následující výstup.
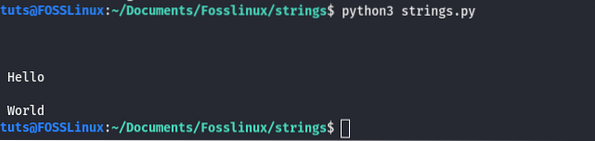
Jak vidíme v kódu, že nové řádky se přidávají automaticky místo „\ n“. To je místo, kde úniková sekvence přichází do hry. V pythonu je přítomno mnoho sekvenčních znaků. Zde je všechny uvedu; můžete vyzkoušet všechny a zjistit, jak jednotlivé fungují.
- \ ': Používá se k poskytnutí jediné nabídky v řetězci. Stejně jako na některých místech nemůžeme dávat jednotlivé uvozovky přímo.
- \\: Tento znak se používá k reprezentaci zpětného lomítka, protože na mnoha místech nemůžeme použít \ přímo.
- \ n: Tento znak představuje znak nového řádku, který přidá nový řádek.
- : představuje návrat vozíku.
- \ t: představuje kartu.
- \ b: představuje znak backspace.
- \F: Tato úniková sekvence se používá k reprezentaci formfeedu.
- \ ooo: Tento znak se používá k vyjádření osmičkové hodnoty.
- \ xhh: Tento znak se používá k reprezentaci hexadecimální hodnoty.
- \A: Tento znak slouží k upozornění.
- \ s: Tento znak se používá k poskytnutí mezery.
- \proti: představuje svislou záložku.
Řetězcové metody
Naučili jsme se mnoho věcí o řetězcích pythonu, ale tato část je mnohem užitečnější než kterákoli jiná část tohoto článku. Python přichází s velkým množstvím integrovaných funkcí pro práci s řetězci. Jejich použitím můžeme snadno provádět mnoho operací s řetězci.
Transformace řetězcových případů
Máme několik vestavěných funkcí, které lze použít k transformaci řetězcových případů. Pojďme je všechny probrat.
tětiva.velká písmena ()
Tato metoda se používá k vydělávání na cílovém řetězci. Když použijeme metodu jako tětiva.kapitalizovat, vrátí řetězec velkým písmem, tj.E., transformace prvního znaku na velká písmena a všech ostatních znaků na malá písmena. Chcete-li zobrazit praktickou ukázku své pracovní kopie a spustit následující kód ve vašem IDE Pythonu.
string = "fosslinux"Použili jsme velká písmena () metoda objektu String, velká písmena. Při spuštění kódu získáme následující výstup.
tisk (řetězec.velká písmena ())

.horní()
Tato metoda se používá k transformaci řetězce na velká písmena, tj.E., velká písmena všechny znaky přítomné v řetězci.
Příklad:
string = "Fosslinux"
tisk (řetězec.horní())
Výstup:

tětiva.dolní()
Tato metoda se používá k transformaci řetězce na malá písmena, tj.E., změní všechny znaky přítomné v řetězci na malá písmena.
Příklad:
string = "FOSSLinux"
tisk (řetězec.dolní())
Výstup:

tětiva.swapcase ()
Jedná se o skvělou metodu pro výměnu velkých a malých písmen znaků řetězce. Převádí malá písmena na velká písmena a naopak řetězce. Chcete-li vidět jeho fungování, stačí zkopírovat a spustit následující kód.
string = "FOSSlinux"
tisk (řetězec.swapcase ())
Výstup:

tětiva.titul()
Opět se jedná o vynikající metodu manipulace s řetězci, protože transformuje první znak každého slova přítomného v řetězci na velká písmena.
Příklad:
string = "Fosslinux je skvělý"
tisk (řetězec.titul())
Výstup:

Možná jste si všimli rozdílu mezi velká písmena () a titul() metoda. The velká písmena () metoda pouze velká písmena prvního znaku prvního slova řetězce, zatímco titul() metoda velká písmena prvního znaku každého slova přítomného v řetězci.
Klasifikace znaků
Máme také způsoby, jak zkontrolovat velikost řetězce, ať už velká, malá atd. Pojďme o nich stručně diskutovat s příklady.
tětiva.isalnum ()
Tato metoda se používá ke kontrole, zda řetězec obsahuje pouze alfanumerická čísla, či nikoli, tj.E., všechny jeho znaky musí být čísla nebo abecedy, ale žádné jiné znaky, včetně mezer.
Příklad:
string1 = "Fosslinux123"
string2 = "Fosslinux je skvělý"
string3 = "Fosslinux @ # 123"
tisk (řetězec1.isalnum ()) # obsahuje pouze abecedu a čísla
tisk (řetězec2.isalnum ()) # obsahují mezery
tisk (řetězec3.isalnum ()) # obsahují speciální znaky
Výstup:

tětiva.isalpha ()
Tato metoda řetězce je podobná výše uvedené metodě, ale kontroluje pouze abecedy, nikoli čísla v řetězci, což znamená, že řetězec musí obsahovat pouze abecedy. Například spusťte následující kód.
string1 = "Fosslinux123"
string2 = "Fosslinux"
tisk (řetězec1.isalpha ()) # obsahují abecedu a čísla
tisk (řetězec2.isalpha ()) # obsahují pouze abecedu
Za první dostaneme False, protože obsahuje čísla, a za další dostaneme True, protože obsahuje pouze abecedy.
Výstup:

tětiva.isdigit ()
Tato metoda je podobná té výše uvedené, ale místo abeced kontroluje, zda se řetězec skládá pouze z číslic. Vrátí True, pokud jsou všechny znaky v řetězci číslice; else vrátí False.
tětiva.isidentifier ()
To je také skvělá metoda řetězce v pythonu. Pomocí této metody můžeme zkontrolovat, zda je řetězec platným identifikátorem pythonu nebo ne. Pravidla pro výběr platného identifikátoru pythonu jsem diskutoval v základech tutoriálu pythonu.
Příklad:
string1 = "Fosslinux123"
string2 = "123Fosslinux"
string3 = "_Fosslinux"
string4 = "Fosslinux @ 1234"
tisk (řetězec1.isidentifier ()) # Pravda
tisk (řetězec2.isidentifier ()) # False (zahájeno čísly)
tisk (řetězec3.isidentifier ()) # Pravda
tisk (řetězec4.isidentifier ()) # False (obsahovat speciální znaky @)
Výstup:

tětiva.islower ()
Tato metoda řetězce kontroluje, zda jsou všechny znaky řetězce malými písmeny. Pokud ano, vrátí True, vrátí False.
tětiva.isupper ()
Tato metoda řetězce kontroluje, zda jsou všechny znaky přítomné v řetězci velká. Pokud ano, pak vrátí True, jiné vrátí False.
tětiva.istitle ()
The istitle () metoda řetězce vrátí True, pokud je první abeceda všech slov přítomných v řetězci velká a všechny ostatní znaky jsou malá.
tětiva.isprintable ()
Vrátí True, pokud jsou všechny znaky přítomné v řetězci tisknutelné, tj.E., neunikající postavy; jinak vrátí False. Chcete-li zjistit, jak to funguje, spusťte následující kód.
string1 = "Fosslinux"
string2 = "\ nFosslinux"
tisk (řetězec1.isprintable ()) # Pravda
tisk (řetězec2.isprintable ()) # False (obsahuje nový znak řádku)
Výstup:

tětiva.isspace ()
The tětiva.isspace () metoda vrátí True, pokud jsou všechny znaky řetězce prázdné znaky; jinak vrátí False.
Další důležité funkce
tětiva.počet()
Metoda count () objektu String se používá k získání počtu výskytů zadané hodnoty.
Příklad:
string = "Fosslinux"
tisk (řetězec.count ("s"))
Ve výše uvedeném kódu jsme použili počet() metoda pro získání počtu zobrazení znaku „s“ v řetězci „Fosslinux.“
Výstup:

tětiva.začíná s()
Tato metoda řetězce kontroluje, zda řetězec začíná podřetězcem uvedeným v argumentu metody. Chcete-li vidět praktické ukázky jeho fungování, zkopírujte a spusťte níže uvedený kód v prostředí Python IDE.
string = "Fosslinux"
tisk (řetězec.začíná s („F“))
tisk (řetězec.začíná s („Fo“))
tisk (řetězec.začíná s („Foss“))
tisk (řetězec.začíná s („Fosss“))
Při spuštění výše uvedeného kódu dostaneme True pro první tři, zatímco poslední vrátí False, jak je znázorněno na následujícím výstupním obrázku.

tětiva.končí s()
Je to podobné jako u výše uvedené metody, ale rozdíl je v tom, že zatímco předchozí kontroluje začátek řetězce, bude kontrolovat na konci řetězce.
tětiva.nalézt()
Metoda find () objektu String je důležitou metodou k vyhledání znaku nebo podřetězce v řetězci. Přijímá podřetězec jako argument a vrací index podřetězce, pokud je v řetězci přítomen; else vrátí -1.
Příklad:
string = "Fosslinux"
tisk (řetězec.najít („lin“))
Při spuštění výše uvedeného kódu dostaneme výstup jako 4, což je počáteční index podřetězce „lin“ ve „Fosslinuxu.“

tětiva.nahradit()
Syntaxe této metody je nahradit (stará, nová). Trvá to dva argumenty; jeden je starý podřetězec a nový je podřetězec. Nahradí všechny staré podřetězce novým podřetězcem v celém řetězci.
Příklad:
string = "Fosslinux"Dostaneme pouze Linux vytištěno na obrazovce jako Foss při spuštění výše uvedeného kódu bude nahrazen mezerami. Výstup:
tisk (řetězec.nahradit ("Foss", ""))

tětiva.rozdělit()
Tato metoda vezme oddělovač jako argument, rozdělí řetězec podle oddělovače a vrátí seznam pythonu.
Příklad:
string = "Fosslinux je skvělé místo, kde se začít učit linux a python"Při spuštění výše uvedeného kódu získáme seznam řetězcových slov. Protože jsme použili funkci split s mezerami jako argumentem, rozděluje řetězec, když získá mezery. Výstup:
tisk (řetězec.split (""))

tětiva.pás()
Tato metoda se používá k odebrání všech předních a koncových mezer z řetězce.
Závěr
To je vše o řetězcích a jejich použití v Pythonu. Procházením tutoriálu získáte představu o tom, jak užitečné je pracovat s řetězci v pythonu. Můžete také vidět návod k použití smyčky for v pythonu, dokonalé smyčky pro iteraci v pythonu. Nakonec, než odejdeme, možná se budete chtít podívat na metodu pro obrácení řetězce v Pythonu, což se hodí při manipulaci s řetězci.


