Apache Kafka
Pro definici na vysoké úrovni si představíme krátkou definici pro Apache Kafka:
Apache Kafka je distribuovaný protokol odolný vůči chybám, horizontálně škálovatelný a potvrzující.
To byla některá slova na vysoké úrovni o Apache Kafkovi. Pojďme zde podrobně pochopit pojmy.
- Distribuováno: Kafka rozděluje data, která obsahuje, na více serverů a každý z těchto serverů je schopen zpracovávat požadavky klientů na sdílení dat, která obsahuje
- Tolerantní k chybám: Kafka nemá jediný bod selhání. V systému SPoF, jako je databáze MySQL, pokud dojde k výpadku serveru hostujícího databázi, je aplikace zašroubována. V systému, který nemá SPoF a sestává z vícenásobných uzlů, i když většina systému spadne, je pro koncového uživatele stále stejný.
- Horizontálně škálovatelné: Tento druh škálování odkazuje na přidání více strojů do existujícího klastru. To znamená, že Apache Kafka je schopen přijímat více uzlů ve svém klastru a neposkytovat žádné prostoje pro požadované upgrady systému. Podívejte se na obrázek níže, abyste pochopili typ škálovacích konceptů:
- Commit Log: Protokol potvrzení je datová struktura stejně jako propojený seznam. Připojuje jakékoli zprávy, které k němu přicházejí, a vždy udržuje jejich pořadí. Data nelze z tohoto protokolu smazat, dokud pro tato data nedosáhnete stanoveného času.
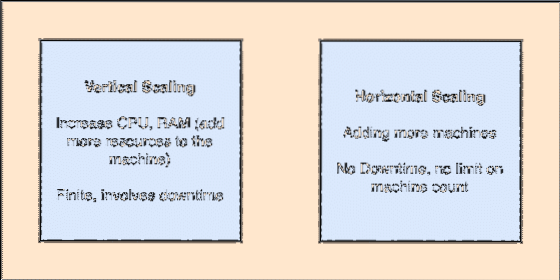
Vertikální a horizontální škálování
Téma v Apache Kafka je stejně jako fronta, kde jsou ukládány zprávy. Tyto zprávy jsou uloženy po nastavitelnou dobu a zpráva je odstraněna až po dosažení této doby, i když byla spotřebována všemi známými spotřebiteli.
Kafka je škálovatelná, protože právě spotřebitelé skutečně ukládají, že jaká zpráva byla načtena jako poslední, jako hodnota „offsetu“. Podívejme se na obrázek, abychom tomu lépe porozuměli: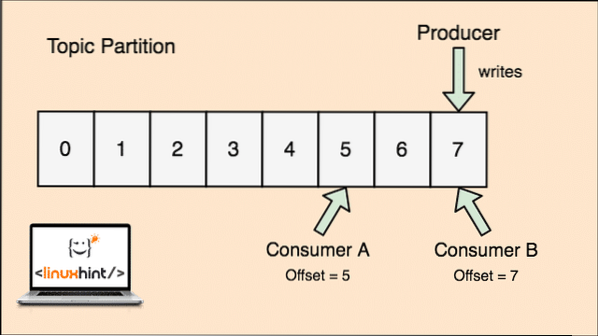
Tématický partion a offset pro spotřebitele v Apache Kafka
Začínáme s Apache Kafkou
Chcete-li začít používat Apache Kafka, musí být na počítači nainstalován. Chcete-li to provést, přečtěte si Instalovat Apache Kafka na Ubuntu.
Ujistěte se, že máte aktivní instalaci Kafky, pokud si chcete vyzkoušet příklady, které uvádíme níže v lekci.
Jak to funguje?
Se společností Kafka Výrobce aplikace publikovat zprávy který dorazí na Kafku Uzel a nikoli přímo spotřebiteli. Z tohoto uzlu Kafka zprávy spotřebovává Spotřebitel aplikace.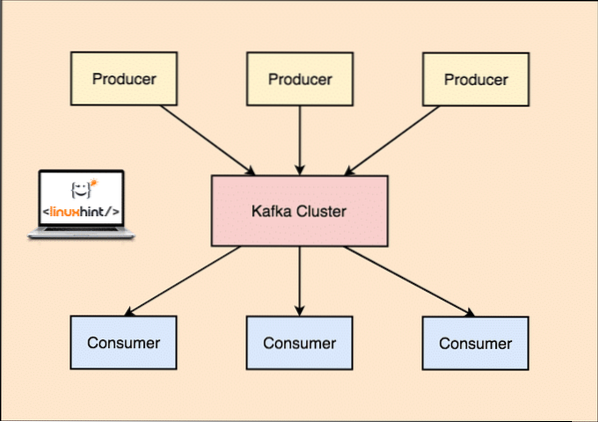
Výrobce a spotřebitel společnosti Kafka
Jelikož jediné téma může získat spoustu dat najednou, je každé téma rozděleno na, aby byla Kafka horizontálně škálovatelná oddíly a každý oddíl může žít na jakémkoli uzlovém stroji klastru. Zkusme to představit:
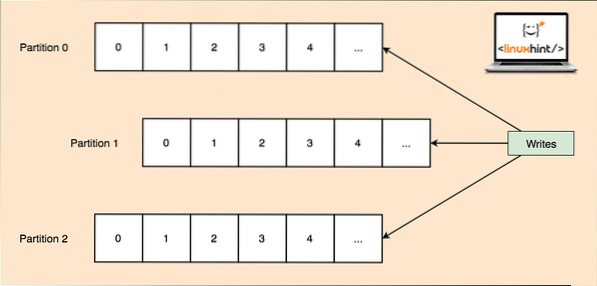
Tématické oddíly
Kafka Broker opět neuchovává záznamy o tom, který spotřebitel spotřeboval kolik paketů dat. To je odpovědnost spotřebitelů sledovat údaje, které spotřebovala.
Perzistence na disk
Kafka přetrvává záznamy zpráv, které získává od producentů na disku, a neuchovává je v paměti. Může vyvstat otázka, jak to dělá věci proveditelnými a rychlými? Bylo za tím několik důvodů, které z něj činí optimální způsob správy záznamů zpráv:
- Kafka postupuje podle protokolu seskupování záznamů zpráv. Producenti vytvářejí zprávy, které se přetrvávají na disk ve velkých blocích, a spotřebitelé tyto záznamy zpráv také spotřebovávají ve velkých lineárních blocích.
- Důvodem, proč jsou zápisy na disk lineární, je to, že díky tomu je čtení rychlejší díky velmi snížené době čtení lineárního disku.
- Lineární diskové operace jsou optimalizovány pomocí Operační systémy také pomocí technik zapisovat a čtení dopředu.
- Moderní OS také používá koncept Ukládání stránek do mezipaměti což znamená, že ukládají do mezipaměti některá data na disku ve volné dostupné paměti RAM.
- Jelikož Kafka uchovává data v jednotných standardních datech v celém toku od výrobce ke spotřebiteli, využívá optimalizace nulového kopírování proces.
Distribuce a replikace dat
Jak jsme studovali výše, že téma je rozděleno na oddíly, každý záznam zprávy se replikuje na více uzlech clusteru, aby se zachovalo pořadí a data každého záznamu v případě, že jeden z uzlů zemře.
I když je oddíl replikován na více uzlech, stále existuje vedoucí oddílu uzel, jehož prostřednictvím aplikace čtou a zapisují data k tématu, a vedoucí replikuje data na dalších uzlech, které se označují jako následovníci tohoto oddílu.
Pokud jsou data záznamu zprávy pro aplikaci velmi důležitá, lze zvýšit bezpečnost záznamu zprávy v jednom z uzlů zvýšením replikační faktor klastru.
Co je Zookeeper?
Zookeeper je vysoce odolný proti chybám, distribuovaný klíč-hodnota úložiště. Apache Kafka silně závisí na Zookeeperu, aby ukládal mechaniky klastrů, jako je prezenční signál, distribuoval aktualizace / konfigurace atd.).
Umožňuje makléřům Kafky přihlásit se k odběru a vědět, kdykoli dojde k jakékoli změně týkající se vedoucího oddílu a distribuce uzlů.
Aplikace Producer a Consumers přímo komunikují se Zookeeperem aplikace zjistit, který uzel je vedoucím oddílu pro dané téma, aby mohli provádět čtení a zápisy z vedoucího oddílu.
Streamování
Stream Processor je hlavní komponenta v kafkovském klastru, který bere nepřetržitý proud dat záznamu zpráv ze vstupních témat, zpracovává tato data a vytváří proud dat na výstupní témata, která mohou být cokoli, od koše po databázi.
Je zcela možné provádět jednoduché zpracování přímo pomocí rozhraní API producent / spotřebitel, ačkoli pro složité zpracování, jako je kombinování streamů, poskytuje Kafka integrovanou knihovnu API Streams, ale mějte na paměti, že toto API je určeno k použití v našem vlastním codebase a není běžet na brokera. Funguje podobně jako spotřebitelské API a pomáhá nám škálovat práci se zpracováním proudu na více aplikací.
Kdy použít Apache Kafka?
Jak jsme studovali v předchozích částech, Apache Kafka lze použít k řešení velkého počtu záznamů zpráv, které mohou patřit k téměř nekonečnému počtu témat v našich systémech.
Apache Kafka je ideálním kandidátem, pokud jde o používání služby, která nám umožňuje sledovat architekturu založenou na událostech v našich aplikacích. To je způsobeno jeho schopnostmi perzistence dat, odolnosti proti chybám a vysoce distribuované architektury, kde se kritické aplikace mohou spolehnout na jeho výkon.
Škálovatelná a distribuovaná architektura Kafky velmi usnadňuje integraci s mikroslužbami a umožňuje aplikaci oddělit se od mnoha obchodních logik.
Vytváření nového tématu
Můžeme vytvořit testovací téma testování na serveru Apache Kafka pomocí následujícího příkazu:
Vytvoření tématu
sudo kafka-topic.sh --create --zookeeper localhost: 2181 --replication-factor 1--oddíly 1 - topické testování
S tímto příkazem se vrátíme: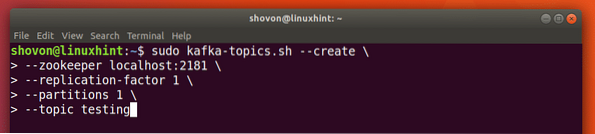
Vytvořit nové téma Kafka
Bude vytvořeno testovací téma, které můžeme potvrdit zmíněným příkazem:
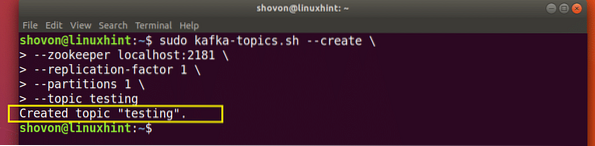
Potvrzení vytvoření tématu Kafka
Psaní zpráv na téma
Jak jsme studovali dříve, jedním z API přítomných v Apache Kafce je Producent API. Toto API použijeme k vytvoření nové zprávy a publikování k tématu, které jsme právě vytvořili:
Psaní zprávy na téma
sudo kafka-console-producer.sh --broker-list localhost: 9092 --topické testováníPodívejme se na výstup tohoto příkazu:
Publikovat zprávu na téma Kafka
Jakmile stiskneme klávesu, uvidíme nový znak šipky (>), což znamená, že nyní můžeme inout data:

Psaní zprávy
Jednoduše zadejte něco a stiskněte pro spuštění nového řádku. Napsal jsem 3 řádky textů:
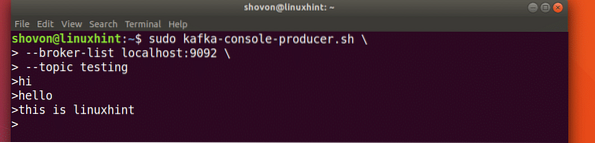
Čtení zpráv z tématu
Nyní, když jsme zveřejnili zprávu na téma Kafka, které jsme vytvořili, tato zpráva tam bude nějakou konfigurovatelnou dobu. Nyní si ji můžeme přečíst pomocí Spotřebitelské API:
Čtení zpráv z tématu
sudo kafka-console-consumer.sh --zookeeper localhost: 2181 --testování témat - od začátku
S tímto příkazem se vrátíme:
Příkaz ke čtení zprávy z tématu Kafka
Budeme moci zobrazit zprávy nebo řádky, které jsme napsali pomocí Producer API, jak je uvedeno níže:
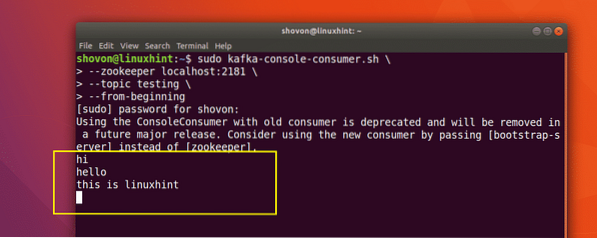
Pokud napíšeme další novou zprávu pomocí Producer API, zobrazí se také okamžitě na straně spotřebitele:
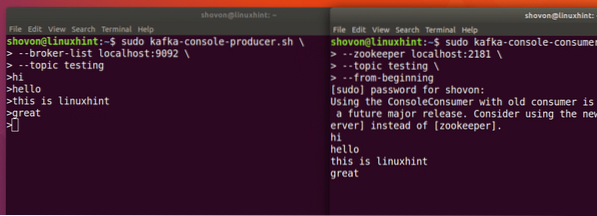
Publikujte a spotřebujte současně
Závěr
V této lekci jsme se podívali na to, jak začneme používat Apache Kafka, což je vynikající Zprostředkovatel zpráv a může fungovat také jako speciální jednotka pro persistenci dat.


