Data Science
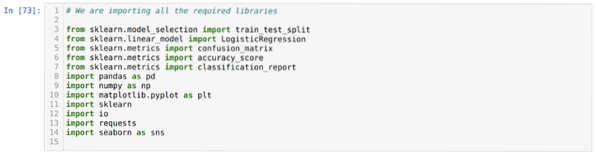
Logistická regrese v Pythonu
Logistická regrese je algoritmus klasifikace strojového učení. Logistická regrese je také podobná lineární regrese. Ale hlavní rozdíl mezi logistickou...
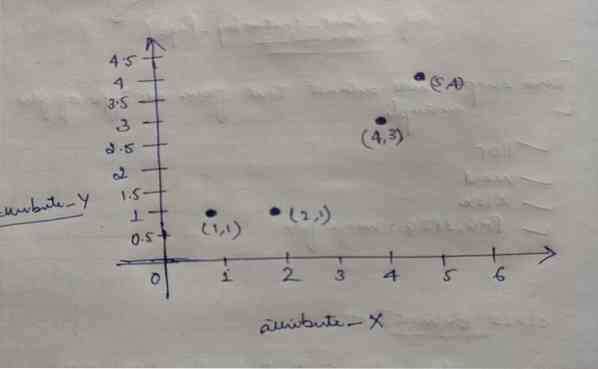
K-znamená shlukování
Kód tohoto blogu je spolu s datovou sadou k dispozici na následujícím odkazu https: // github.com / shekharpandey89 / k-means K-Means shlukování je al...

Jak vytvořit kontingenční tabulku v Pandas Python
V pythonu pandy obsahuje kontingenční tabulka funkce součty, počty nebo agregace odvozené z datové tabulky. Agregační funkce lze použít na různé funkc...
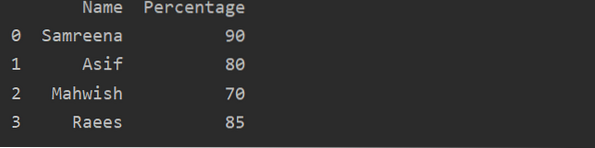
Jak vytvořit Pandas DataFrame v Pythonu?
Pandas DataFrame je 2D (dvourozměrná) anotovaná datová struktura, ve které jsou data srovnávána v tabulkové formě s různými řádky a sloupci. Pro snazš...
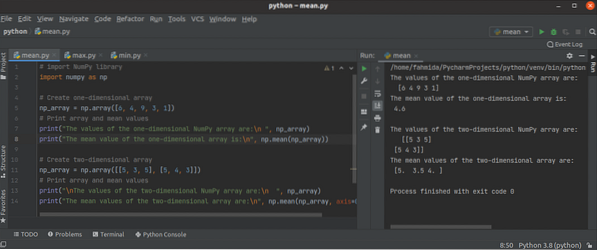
Jak používat funkce Python NumPy mean (), min () a max ()?
Knihovna Python NumPy má mnoho agregačních nebo statistických funkcí pro provádění různých typů úkolů pomocí jednorozměrného nebo vícerozměrného pole....
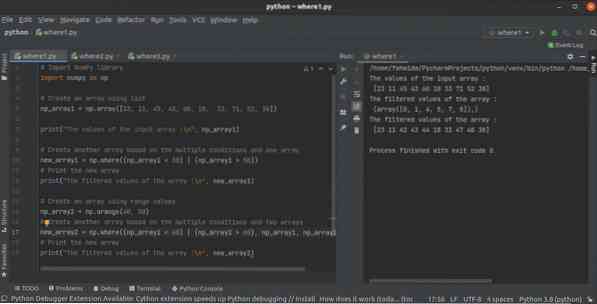
Jak používat python NumPy where () funkce s více podmínkami
Knihovna NumPy má mnoho funkcí k vytvoření pole v pythonu. kde () funkce je jedním z nich k vytvoření pole z jiného pole NumPy na základě jedné nebo v...
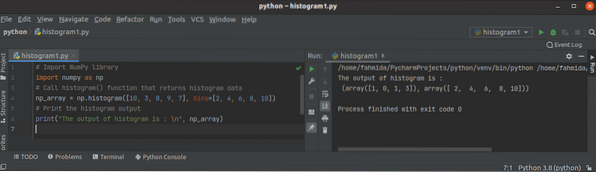
Výukový program histogramu () Pythonu NumPy
Histogram je mapování intervalů na frekvence. Používá se k aproximaci funkce hustoty pravděpodobnosti konkrétní proměnné. Je známý také jako sloupcový...
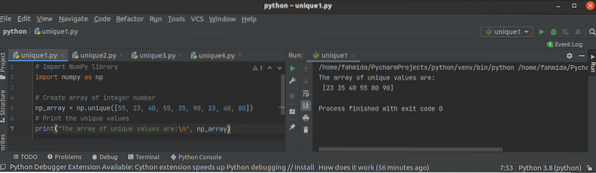
Jak používat funkci Python NumPy unique ()
Knihovna NumPy se používá v pythonu k vytvoření jednoho nebo více dimenzionálních polí a má mnoho funkcí pro práci s polem. Funkce unique () je jednou...
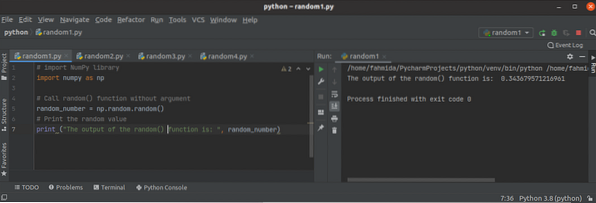
Jak používat náhodnou funkci Python NumPy?
Když se hodnota čísla změní při každém spuštění skriptu, pak se toto číslo nazývá náhodné číslo. Náhodná čísla se používají hlavně pro různé typy test...


