Syntax
Grep [vzor] [název souboru]
Po použití grepu přichází vzor. Vzor implikuje způsob, jakým jej chceme použít k odstranění dalšího prostoru v datech. Po vzoru je popsán název souboru, jehož prostřednictvím se vzor provádí.
Předpoklad
Abychom snadno pochopili užitečnost grepu, musíme mít v našem systému nainstalovaný Ubuntu. Poskytněte podrobnosti o uživateli poskytnutím uživatelského jména a hesla, abyste měli oprávnění pro přístup k aplikacím systému Linux. Po přihlášení otevřete aplikaci a vyhledejte terminál nebo použijte klávesovou zkratku ctrl + alt + T.
Použitím klíčového slova [: blank:]
Předpokládejme, že máme soubor s názvem bfile, který má textovou příponu. Soubor můžete vytvořit buď v textovém editoru, nebo pomocí příkazového řádku v terminálu. Vytvoření souboru na terminálu, včetně následujících příkazů.
$ Echo „text, který se má zadat do souboru“> název souboru.txtNení-li již soubor vytvořen, není třeba jej vytvářet. Stačí jej zobrazit pomocí připojeného příkazu:
$ echo název souboru.txtText napsaný v těchto souborech obsahuje mezery mezi nimi, jak je vidět na obrázku níže.
![]()
Tyto prázdné řádky lze odstranit pomocí prázdného příkazu k ignorování prázdných mezer mezi slovy nebo řetězci.
$ egrep '^ [[: blank]] * [^ [: blank:] #] bfile.txt![]()
Po použití dotazu budou mezery mezi řádky odstraněny a výstup již nebude obsahovat další mezeru. První slovo je zvýrazněno, protože mezery mezi posledním slovem řádku a mezi prvními slovy dalšího řádku jsou odstraněny. Můžeme také použít podmínky na stejný příkaz grep přidáním této prázdné funkce, abychom odstranili zbytečné místo ve výstupu.
Použitím [: mezera:]
Zde je vysvětlen další příklad ignorování prostoru.
Aniž bychom zmínili příponu souboru, nejprve pomocí příkazu zobrazíme existující soubor.
$ kočičí soubor20![]()
Podívejme se na to, jak je kromě klíčového slova [: space:] odstraněn další prostor pomocí příkazu grep. Volba Grep -v pomůže vytisknout řádky, které postrádají prázdné řádky a zvláštní mezery, které jsou také zahrnuty ve formě odstavce.
$ grep -v '^ [[; mezera:]] * $' soubor20Uvidíte, že jsou odstraněny další řádky a výstup je v sekvenční podobě po řádcích. Tak je metodologie grep -v tak užitečná při dosahování požadovaného cíle.
![]()
Zmínka o příponách souborů omezuje funkčnost grepu tak, aby fungovala pouze na konkrétních příponách souborů, tj.E., .text nebo .mp3. Jak provádíme zarovnání textového souboru, vezmeme fileg.txt jako ukázkový soubor. Nejprve zobrazíme text, který je v něm, pomocí funkce $ cat. Výstup je následující:
![]()
Použitím příkazu byl získán náš výstupní soubor. Zde vidíme data bez mezer mezi řádky, které jsou postupně zapisovány.
$ grep -v '^ [[: space:]] * $' fileg.txt![]()
Kromě dlouhých příkazů můžeme v Linuxu a Unixu použít i krátké písemné příkazy k implementaci grep podporuje zkratkové znaky v něm.
$ grep '\ s' název souboru.txtViděli jsme, jak je výstup získán použitím příkazů ze vstupu. Zde se naučíme, jak je vstup udržován zpět z výstupu.
$ grep '\ S' název souboru.txt> tmp.txt && mv tmp.název souboru txt.txtZde použijeme dočasný textový soubor s příponou textu s názvem tmp.
Použitím ^ #
Stejně jako další popsané příklady použijeme příkaz na textový soubor pomocí příkazu cat. Můžeme také zobrazit text pomocí příkazu echo.
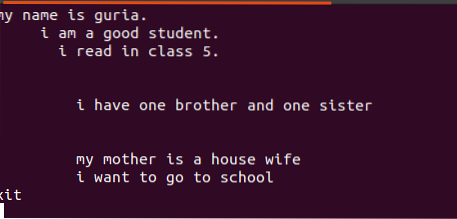
$ echo název souboru.txtTextový soubor obsahuje 4 řádky, mezi nimiž je mezera. Tyto řádky mezery lze snadno odstranit pomocí konkrétního příkazu.
![]()
Pravidelné rozšířené operace jsou povoleny pomocí -E, což umožňuje všechny regulární výrazy, zejména potrubí. Trubka se používá jako volitelná podmínka „nebo“ v jakémkoli vzoru.„^ #“. To ukazuje shodu textových řádků v souboru, který začíná znakem #. „^ $“ Bude odpovídat všem volným mezerám v textu nebo prázdným řádkům.
![]()
Výstup ukazuje úplné odstranění mezery mezi řádky v datovém souboru. V tomto příkladu jsme viděli, že v příkazu, který „^ #“ je na prvním místě, což znamená, že text je porovnán jako první. „^ $“ Přichází za | operátor, takže volné místo se poté shoduje.
Použitím ^ $
Stejně jako výše uvedený příklad přijdeme se stejnými výsledky, protože příkaz je téměř stejný. Vzor je však psán opačně. Soubor22.txt je soubor, který použijeme při odstraňování mezer.
![]()
Stejná metodika se používá kromě práce s prioritou. Podle tohoto příkazu bude nejprve uzavřeno volné místo a poté budou porovnány textové soubory. Výstup poskytne posloupnost řádků odstraněním mezer v nich.
![]()
Další jednoduché příkazy
- Grep '^…' název souboru.
- Grep '.' Název souboru
Oba jsou tak jednoduché a pomáhají při odstraňování mezer v textových řádcích.
Závěr
Odstranění zbytečných mezer v souborech pomocí regulárních výrazů je docela snadný přístup k dosažení plynulého sledu dat a zachování konzistence. Příklady jsou vysvětleny podrobně, aby se zlepšily vaše informace týkající se daného tématu.


