Apache Spark je nástroj pro analýzu dat, který lze použít ke zpracování dat z HDFS, S3 nebo jiných zdrojů dat v paměti. V tomto příspěvku nainstalujeme Apache Spark na Ubuntu 17.10 strojů.
Verze Ubuntu
V této příručce budeme používat Ubuntu verze 17.10 (GNU / Linux 4.13.0-38-generic x86_64).
Apache Spark je součástí ekosystému Hadoop pro Big Data. Zkuste nainstalovat Apache Hadoop a vytvořte s ním ukázkovou aplikaci.
Aktualizace stávajících balíčků
Pro spuštění instalace pro Spark je nutné, abychom náš stroj aktualizovali o nejnovější dostupné softwarové balíčky. Můžeme to udělat pomocí:
sudo apt-get update && sudo apt-get -y dist-upgradeProtože Spark je založen na Javě, musíme si jej nainstalovat na náš stroj. Můžeme použít libovolnou verzi Java nad Java 6. Zde budeme používat Java 8:
sudo apt-get -y install openjdk-8-jdk-headlessStahování souborů Spark
Na našem stroji nyní existují všechny potřebné balíčky. Jsme připraveni stáhnout požadované soubory Spark TAR, abychom je mohli začít nastavovat a spustit ukázkový program také se Sparkem.
V této příručce budeme instalovat Spark v2.3.0 k dispozici zde:
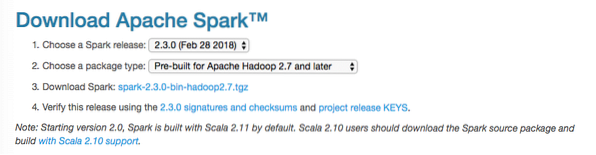
Stránka ke stažení Spark
Pomocí tohoto příkazu stáhněte odpovídající soubory:
wget http: // www-us.apache.org / dist / spark / spark-2.3.0 / jiskra-2.3.0-bin-hadoop2.7.tgzV závislosti na rychlosti sítě to může trvat až několik minut, protože soubor má velkou velikost:
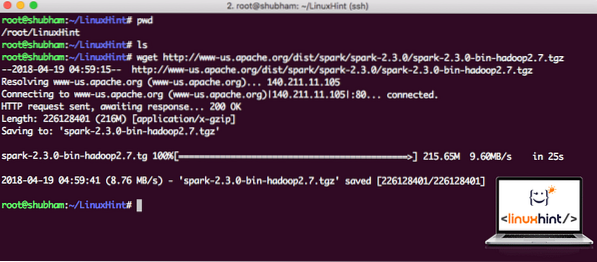
Stahování Apache Spark
Nyní, když máme stažený soubor TAR, můžeme extrahovat v aktuálním adresáři:
tar xvzf spark-2.3.0-bin-hadoop2.7.tgzBude to trvat několik sekund, protože archiv má velkou velikost souboru:
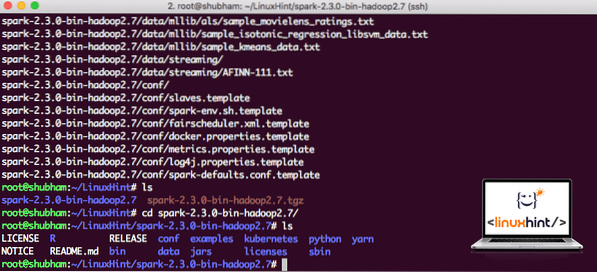
Archivované soubory ve Sparku
Pokud jde o budoucí upgrade Apache Spark, může to kvůli aktualizacím Path způsobit problémy. Těmto problémům se lze vyhnout vytvořením měkkého odkazu na Spark. Spuštěním tohoto příkazu vytvořte softlink:
ln -s spark-2.3.0-bin-hadoop2.7 jiskraPřidání Spark na cestu
Chcete-li spustit skripty Spark, přidáme jej nyní na cestu. Chcete-li to provést, otevřete soubor bashrc:
vi ~ /.bashrcPřidejte tyto řádky na konec .soubor bashrc, aby cesta mohla obsahovat cestu ke spustitelnému souboru Spark:
SPARK_HOME = / LinuxHint / sparkexport PATH = $ SPARK_HOME / bin: $ PATH
Soubor nyní vypadá takto:
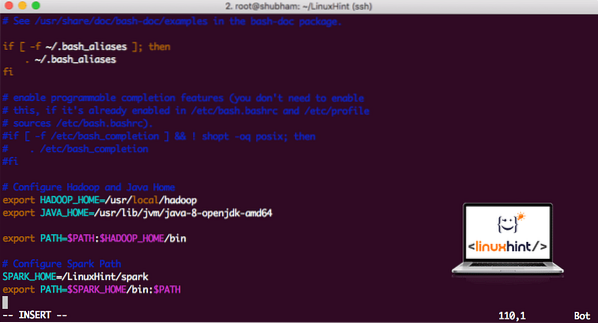
Přidání Spark na PATH
Chcete-li aktivovat tyto změny, spusťte následující příkaz pro soubor bashrc:
zdroj ~ /.bashrcSpuštění Spark Shell
Nyní, když jsme přímo mimo adresář jisker, spusťte následující příkaz a otevřete apark shell:
./ spark / bin / spark-shellUvidíme, že Spark shell je nyní otevřený:
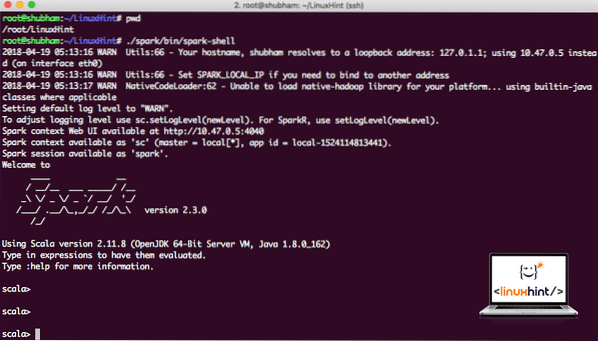
Spouštění Spark shell
Na konzole vidíme, že Spark také otevřel Web Console na portu 404. Pojďme to navštívit:
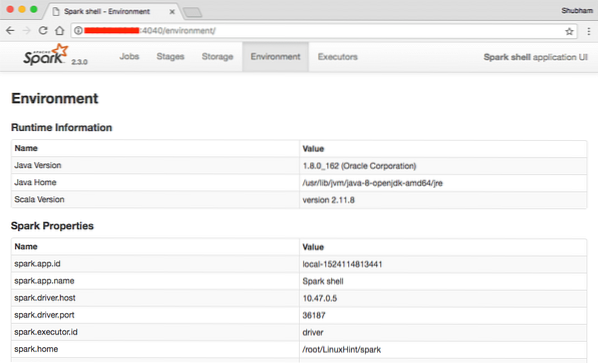
Webová konzole Apache Spark
I když budeme pracovat na samotné konzoli, webové prostředí je důležitým místem, na které se můžete podívat, když provádíte těžké úlohy Spark, abyste věděli, co se děje v každé Spark Job, kterou provádíte.
Zkontrolujte verzi prostředí Spark jednoduchým příkazem:
sc.verzeVrátíme něco jako:
res0: Řetězec = 2.3.0Vytvoření ukázkové aplikace Spark se Scalou
Nyní vytvoříme ukázkovou aplikaci Word Counter s Apache Spark. Chcete-li to provést, nejprve načtěte textový soubor do kontextu Spark na prostředí Spark:
scala> var Data = sc.textFile ("/ root / LinuxHint / spark / README.md ")Údaje: org.apache.jiskra.rdd.RDD [řetězec] = / root / LinuxHint / spark / README.md MapPartitionsRDD [1] na textFile v: 24
scala>
Nyní musí být text obsažený v souboru rozdělen na tokeny, které může Spark spravovat:
scala> var tokens = Data.flatMap (s => s.split (""))žetony: org.apache.jiskra.rdd.RDD [String] = MapPartitionsRDD [2] na flatMap v: 25
scala>
Nyní inicializujte počet pro každé slovo na 1:
scala> var tokens_1 = tokeny.mapa (s => (s, 1))tokens_1: org.apache.jiskra.rdd.RDD [(String, Int)] = MapPartitionsRDD [3] na mapě v: 25
scala>
Nakonec vypočítejte frekvenci každého slova souboru:
var sum_each = tokeny_1.reduceByKey ((a, b) => a + b)Je čas podívat se na výstup programu. Sbírejte žetony a jejich příslušné počty:
scala> sum_each.sbírat()res1: Array [(String, Int)] = Array ((balíček, 1), (pro, 3), (programy, 1), (zpracování.,1), (Protože, 1), (The, 1), (stránka) (http: // spark.apache.org / dokumentace.html).,1), (shluk.,1), (its, 1), ([run, 1), (than, 1), (APIs, 1), (have, 1), (Try, 1), (computation, 1), (through, 1 ), (několik, 1), (Tato, 2), (graf, 1), (Úl, 2), (úložiště, 1), ([„Specifikace, 1), (Komu, 2), („ příze “) , 1), (Jednou, 1), ([„Užitečné, 1), (přednost, 1), (SparkPi, 2), (engine, 1), (verze, 1), (soubor, 1), (dokumentace ,, 1), (zpracování ,, 1), (the, 24), (are, 1), (systems.,1), (params, 1), (not, 1), (different, 1), (refer, 2), (Interactive, 2), (R ,, 1), (given.,1), (if, 4), (build, 4), (when, 1), (be, 2), (Tests, 1), (Apache, 1), (thread, 1), (programs ,, 1 ), (včetně 4), (./ bin / run-example, 2), (Spark.,1), (balíček.,1), (1000).count (), 1), (Verze, 1), (HDFS, 1), (D…
scala>
Vynikající! Byli jsme schopni spustit jednoduchý příklad čítače Word pomocí programovacího jazyka Scala s textovým souborem, který je již v systému k dispozici.
Závěr
V této lekci jsme se podívali na to, jak můžeme nainstalovat a začít používat Apache Spark na Ubuntu 17.10 stroj a spusťte na něm také ukázkovou aplikaci.
Přečtěte si více příspěvků založených na Ubuntu zde.


