Z oficiálního popisu je snadné pochopit hodnotu tohoto nástroje. Linux přichází s velkou sbírkou integrovaných nástrojů. Existují některé speciální, které jsou velmi užitečné pro manipulaci s textem. Řadu z nich jsme již pokryli, například Vim, Nano, awk, sed a další nástroje.
Ti, kteří pravidelně pracují s texty, „tr“ bude určitě opravdu, opravdu užitečný. Tento článek ilustruje nejběžnější použití výrazu „tr“ na dostatečných příkladech.
Poznámka: Výukový program bude používat spoustu fiktivních souborů s náhodným obsahem. Všechny náhodné řetězce jsou generovány Náhodný.org.
Umístění
který tr
Toto je úplná cesta příkazového nástroje „tr“.
Základní použití
Pro použití nástroje „tr“ musíte použít následující strukturu příkazů.
trExistují různé možnosti a způsoby manipulace s texty pomocí „tr“. Nejprve se podívejme na tento ukázkový soubor.
demo kočky.txt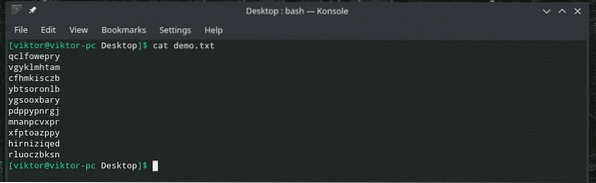
Všechny znaky jsou malé, pravé? Pojďme je transformovat na velká písmena!
demo kočky.txt | tr [: dolní:] [: horní:]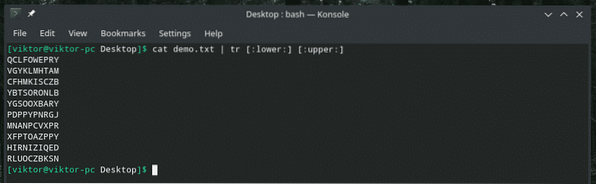
Zde první parametr „tr“ označuje provedení překladu všech malých znaků vstupu. Druhá část říká jejich transformaci na velká písmena na výstupu.
Nyní udělejme opak.
kočka demo1.txt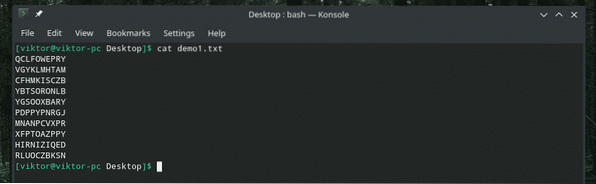
Existuje také jiný způsob provedení stejného úkolu. Pojďme to zkontrolovat.
demo kočky.txt | tr [a-z] [A-Z]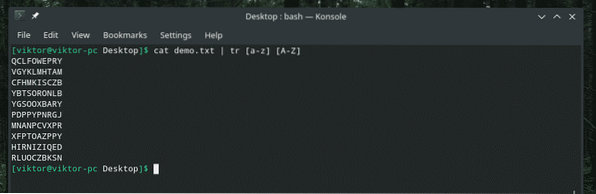
Nyní, místo toho, abychom řekli „tr“ překládat velká písmena na malá písmena nebo malá písmena na velká písmena, řekli jsme identifikovat položky odpovídající rozsahu „a“ až „z“ a přeložit do jejich ekvivalentu z rozsahu „A“ až „Z“.
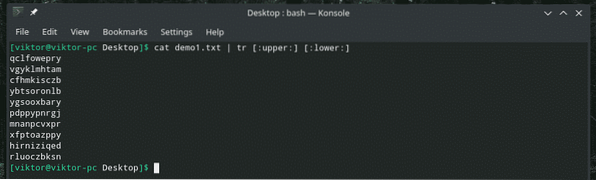
Tuto podobnou metodu lze také použít k překladu malých a velkých písmen.
kočka demo1.txt | tr [A-Z] [a-z]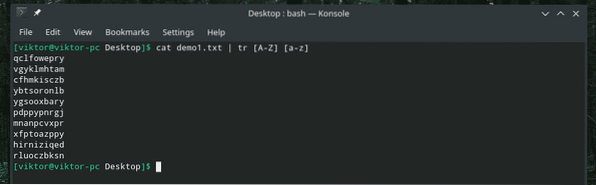
Hra s čísly
Viděli jsme, jak přeložit velká písmena na malá, vpravo? Je čas pohrát si s číslicemi.
Pomocí následujícího příkazu můžeme snadno přeložit všechny číslice (0-9) na jejich ekvivalentní znaky!
kočka demo_digit.txt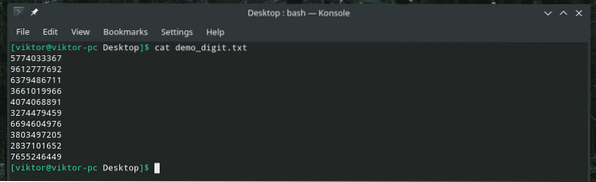
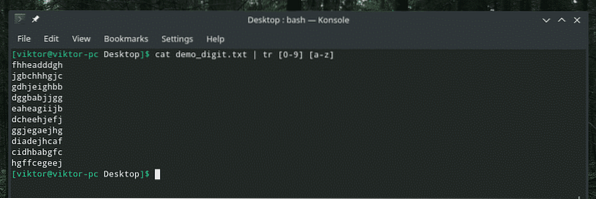
Skvělý! A co velká písmena?
kočka demo_digit.txt | tr [0-9] [A-Z]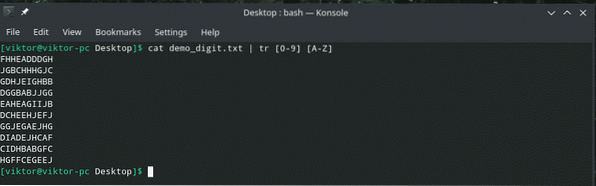
Jednoduché, ale zajímavé, že? Můžeme také transformovat znaky na číslice!
kočka demo_lowercase.txt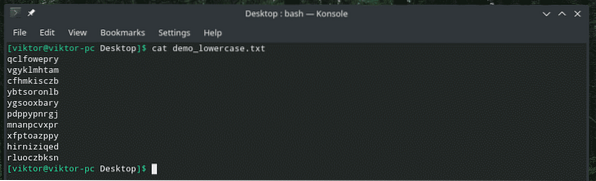
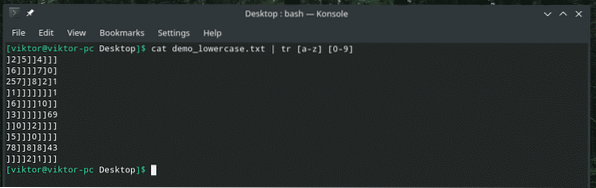
Uh, vypadá to, že se věci rozpadly, že? Můžeme použít pouze 'a' až 'j' k reprezentaci jednotlivých číslic. Pokud existuje nějaký znak, který je mimo tuto vazbu, „tr“ nahradí znak znakem „]“.
Mazání znaků
Jak naznačuje oficiální popis, „tr“ může dělat víc než jen překlad znaků. V následujícím příkladu se podíváme, jak použít „tr“ k odstranění určitých znaků.
kočka náhodně.txt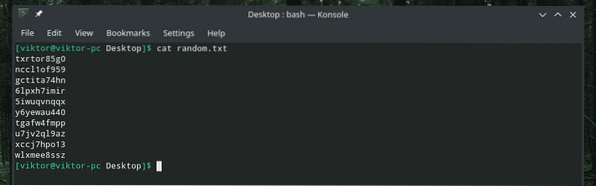
Nyní odstraníme všechna čísla z obsahu.
kočka náhodně.txt | tr -d [0-9]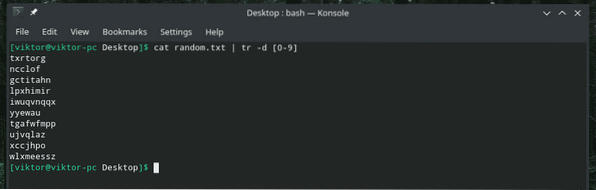
Zde má příznak „-d“ říci „tr“, aby se odstranil, a [0-9] označuje číslice, které se mají odstranit.
Můžeme to udělat i s postavami. Následující příkaz zachová všechna čísla, ale odstraní všechny znaky.
kočka náhodně.txt | tr -d [a-z]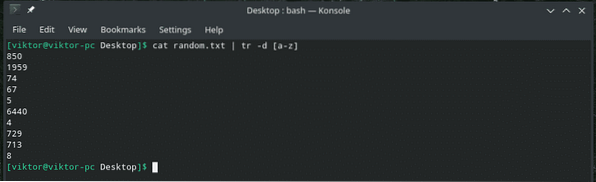
Co takhle odstranit ze souboru pouze jeden konkrétní znak?
kočka demo_lowercase.txt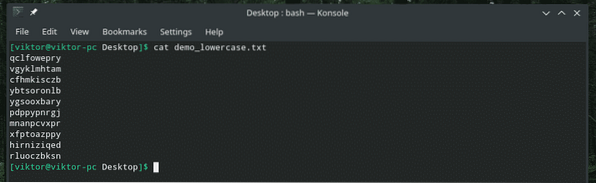
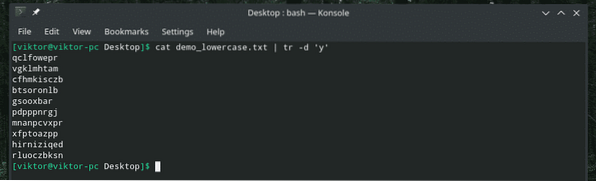
Odstranil ze souboru všechny položky typu „y“.
Mačkání opakovaných znaků
Jsou chvíle, kdy se postava opakuje postupně. Pokud řešíte takové nepříjemné problémy, nechte to „tr“, aby se o to postaralo! Pomocí následujícího příkazu můžete tyto výskyty zmáčknout. V zásadě zachovává počáteční výskyt postavy a odstraňuje další.
Nejprve je třeba zkontrolovat, jak demo soubor vypadá.
kočičí duplikát.txt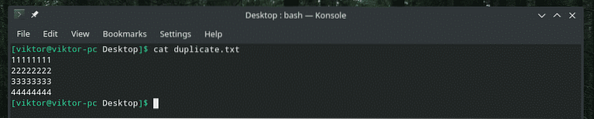
Nyní předejte obsah „tr“.
kočičí duplikát.txt | tr -s [: číslice:]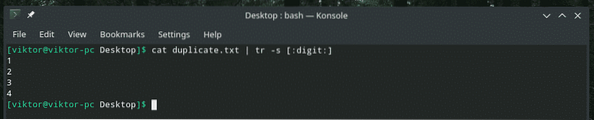
Zde je parametr „-s“ indikátorem provádění akce „squeeze“.
Rozbíjení / slučování vět
Podívejme se na ukázkový soubor.
netopýr duplikát.txt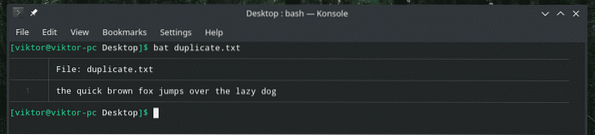
Obsahuje větu s mezerami dělícími slova, správně? Rozdělme slova do nových řádků.
kočičí duplikát.txt | tr "" "\ n"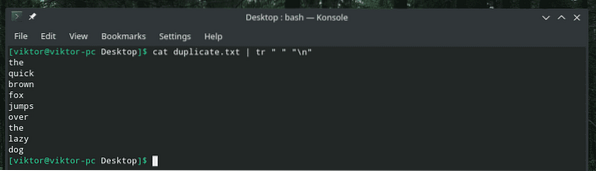
Tento příkaz nahradil všechny znaky mezery znaky nového řádku.
Spojme zlomenou větu znovu do dlouhé věty.
netopýr duplikát.txt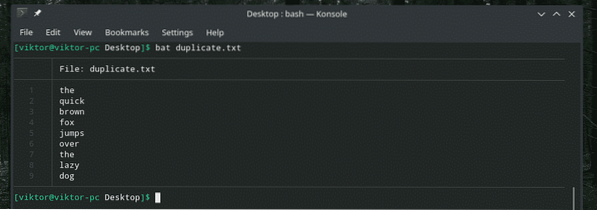

Překládání znaků
Stejně jako jsme dříve překládali znaky, tentokrát uděláme totéž, ale pouze s jedním znakem.
demo kočky.txt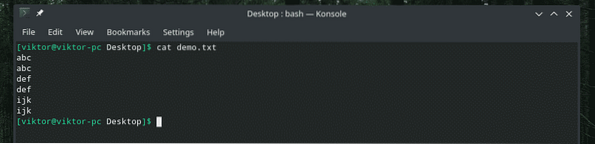
V tomto souboru změňme všechny znaky nového řádku na středník.
demo kočky.txt | tr "\ n" ";"
Musel jsem to zabalit kolem „echa“. Jinak by to vytvořilo nějaký výstup, protože poslední znak nového řádku by byl také přeložen do středníku.
Existuje jiný způsob změny postav. Ten je však těžší ovládat.
kočičí duplikát.txt
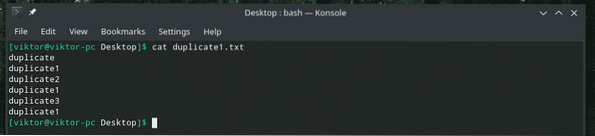

Wow! Pojďme to zabalit kolem „echa“, abychom lépe porozuměli výstupu.
echo $ (duplikát kočky1.txt | tr -c 'd' z ')
Co se tu stalo? Pomocí příznaku „-c“ udrží „tr“ pouze cílový znak beze změny. V případě nesouladu bude každá další postava transformována. Zde byl jakýkoli jiný znak než „b“ nahrazen znakem „z“.
Překlad řetězců
„Tr“ může také pracovat s řetězci. Pojďme provést výměnu řetězce.
kočičí duplikát.txt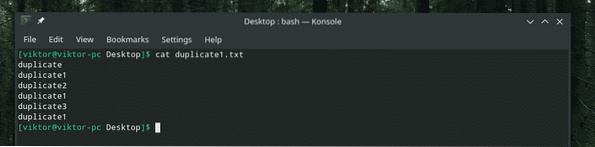
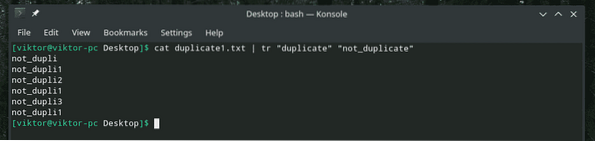
Můj řetězec, který má být nahrazen, je kratší než řetězec, který má být nahrazen, takže se nevejde.
Znakové sady
Nyní jste si všimli, že existuje řada znakových sad podporovaných „tr“. Zatímco řada z nich byla použita ve výše uvedených příkladech, další sady znaků jsou také velmi užitečné. Zde je seznam všech podporovaných seznamů znaků.
Znakové sady POSIX
- [: číslice:]: číslice 0-9
- [: alpha:]: Abecedy a-z a A-Z.
- [: alnum:]: Alfanumerické znaky
- [: punct:]: Interpunkční symboly
- [: mezera:]: Libovolný znak mezery, například mezera, tabulátor, FF, CR, NL, FF atd.
- [: upper:]: Všechny velká písmena abecedy
- [: lower:]: Všechny malé abecedy
- [: cntrl:]: Všechny řídicí znaky (NL, CR, EXT, STX, ACK, SO, DC1, DC2, NAK, ETB, ESC, IS1, IS2, DEL atd.)
Další znakové sady
- [A-Z]: Všechny velká písmena abecedy
- [a-z]: Všechny malé abecedy
- [0-9]: Všechny číslice
Závěrečné myšlenky
Existuje spousta způsobů, jak mohou všechny tyto funkce „tr“ prospět uživatelům. Vždy doporučuji zkontrolovat všechny dostupné možnosti a podrobné průvodce jakýmkoli nástrojem Linux z jejich stránek s informacemi o člověku, informacích a nápovědě, protože mohou nabídnout cennější znalosti.
tr - pomoc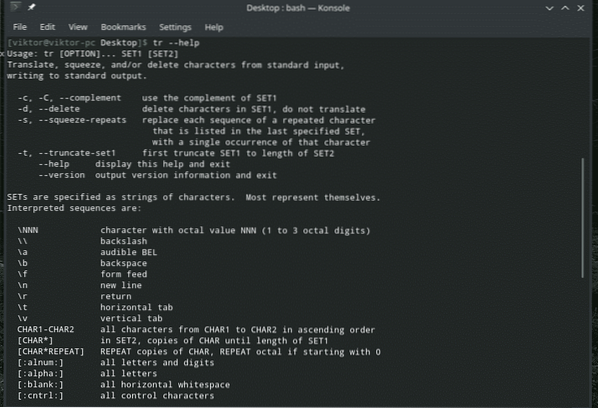
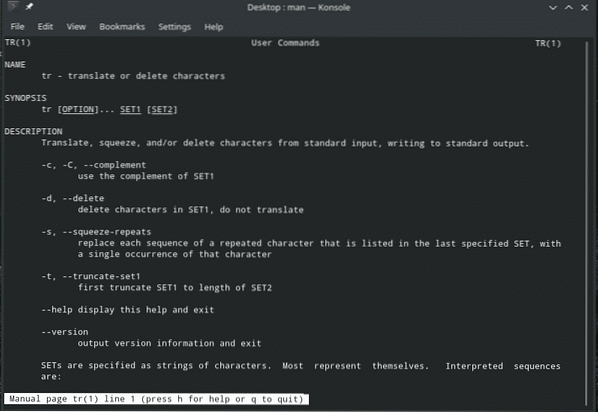
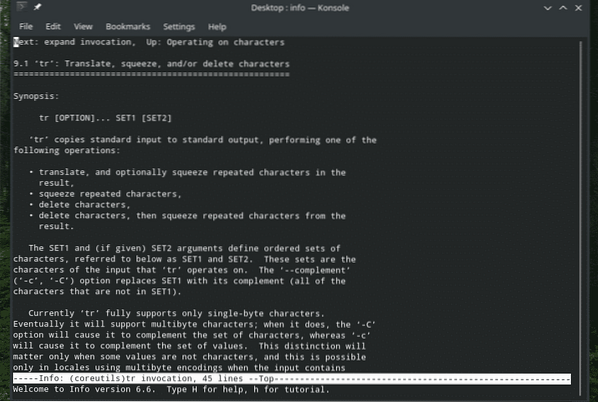
Užívat si!


