Chcete-li začít, musíte mít ve svém systému nainstalován MySQL s jeho obslužnými programy: pracovní stůl MySQL a shell klienta příkazového řádku. Poté byste měli mít některá data nebo hodnoty v databázových tabulkách jako duplikáty. Pojďme to prozkoumat na několika příkladech. Nejprve otevřete shell klienta příkazového řádku na hlavním panelu plochy a na požádání zadejte heslo MySQL.

Našli jsme různé metody, jak najít duplikované v tabulce. Podívejte se na ně jeden po druhém.
Vyhledejte duplikáty v jednom sloupci
Nejprve musíte vědět o syntaxi dotazu použitého ke kontrole a počítání duplikátů pro jeden sloupec.
>> VYBRAT sloupec POČET (sloupec) Z tabulky SKUPINA PODLE sloupce HAVING POČET (sloupec)> 1;Zde je vysvětlení výše uvedeného dotazu:
- Sloupec: Název sloupce, který má být zkontrolován.
- POČET(): funkce sloužící k počítání mnoha duplicitních hodnot.
- SKUPINA VYTVOŘENÁ: klauzule použitá ke seskupení všech řádků podle daného sloupce.
V naší databázi MySQL „data“ jsme vytvořili novou tabulku s názvem „zvířata“, která má duplicitní hodnoty. Má šest sloupců s různými hodnotami, např.G., ID, jméno, druh, pohlaví, věk a cena poskytující informace týkající se různých domácích mazlíčků. Po vyvolání této tabulky pomocí dotazu SELECT získáme níže uvedený výstup v našem klientském prostředí příkazového řádku MySQL.
>> SELECT * FROM data.zvířata;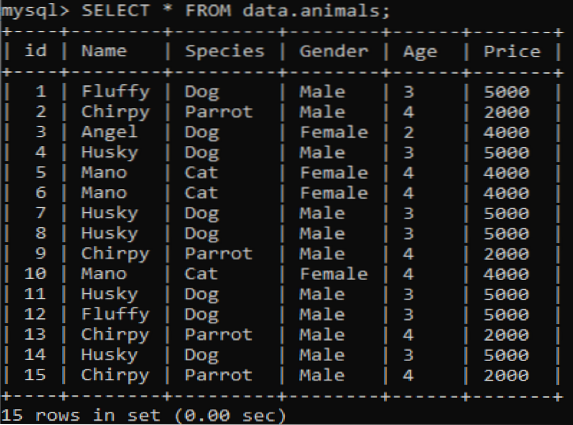
Nyní se pokusíme najít redundantní a opakované hodnoty z výše uvedené tabulky pomocí klauzule COUNT a GROUP BY v dotazu SELECT. Tento dotaz spočítá jména domácích zvířat, která jsou v tabulce uvedena méně než třikrát. Poté se tato jména zobrazí níže.
>> VYBRAT Jméno POČET (Název) Z údajů.zvířata SKUPINA PODLE JMÉNA MÁ POČET (jméno) < 3;
Stejný dotaz použijte k získání různých výsledků při změně počtu POČTŮ pro Názvy domácích mazlíčků, jak je uvedeno níže.
>> VYBRAT Jméno POČET (Název) Z údajů.zvířata SKUPINA PODLE JMÉNA MÁ POČET (jméno)> 3;
Chcete-li získat výsledky pro celkem 3 duplicitní hodnoty pro Názvy domácích zvířat, jak je uvedeno níže.
>> VYBRAT Jméno POČET (Název) Z údajů.zvířata SKUPINA PODLE JMÉNA MÁ POČET (jméno) = 3;
Vyhledejte duplikáty ve více sloupcích
Syntaxe dotazu ke kontrole nebo počítání duplikátů pro více sloupců je následující:
>> SELECT col1, COUNT (col1), col2, COUNT (col2) FROM table GROUP BY col1, col2 HAVING COUNT (col1)> 1 AND COUNT (col2)> 1;Zde je vysvětlení výše uvedeného dotazu:
- col1, col2: název sloupců, které mají být zkontrolovány.
- POČET(): funkce sloužící k počítání několika duplicitních hodnot.
- SKUPINA VYTVOŘENÁ: klauzule použitá ke seskupení všech řádků podle daného konkrétního sloupce.
Používali jsme stejnou tabulku zvanou „zvířata“, která měla duplicitní hodnoty. Získali jsme níže uvedený výstup při použití výše uvedeného dotazu pro kontrolu duplicitních hodnot ve více sloupcích. Zkontrolovali jsme a počítali duplicitní hodnoty pro sloupce Pohlaví a Cena, zatímco byly seskupeny podle sloupce Cena. Zobrazí se pohlaví zvířat a jejich ceny, které jsou v tabulce umístěny jako duplikáty ne více než 5.
>> VYBERTE Gender, POČET (Pohlaví), Cena, POČET (Cena) Z údajů.zvířata SKUPINA PODLE Cena HAVING COUNT (Cena) < 5 AND COUNT(Gender) < 5;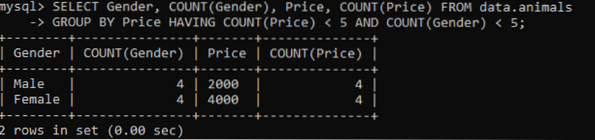
Hledání duplikátů v jedné tabulce pomocí INNER JOIN
Tady je základní syntaxe pro hledání duplikátů v jedné tabulce:
>> SELECT col1, col2, table.col FROM table INNER JOIN (SELECT col FROM table GROUP BY col HAVING COUNT (col1)> 1) temp ON table.col = tepl.col;Zde je popis režijního dotazu:
- Col: název sloupce, který má být zkontrolován a vybrán pro duplikáty.
- Teplota: klíčové slovo pro použití vnitřního spojení na sloupec.
- Stůl: název tabulky, která má být zkontrolována.
Máme novou tabulku „order2“ s duplicitními hodnotami ve sloupci OrderNo, jak je uvedeno níže.
>> SELECT * FROM data.order2;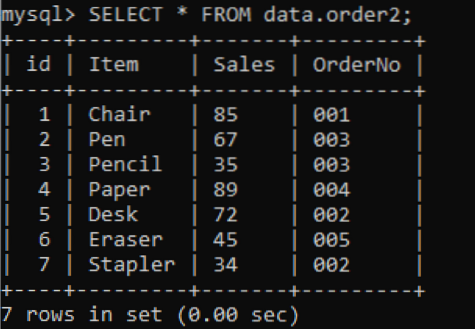
Vybíráme tři sloupce: Položka, Prodej, Číslo objednávky, které se mají zobrazit na výstupu. Zatímco sloupec OrderNo slouží ke kontrole duplikátů. Vnitřní spojení vybere hodnoty nebo řádky s hodnotami položek více než jednou v tabulce. Po provedení získáme níže uvedené výsledky.
>> VYBRAT položku, prodej, objednávku2.OrderNo FROM data.order2 INNER JOIN (VYBERTE OrderNo FROM data.order2 GROUP BY OrderNo HAVING COUNT (Item)> 1) temp ON order2.OrderNo = temp.Objednávka číslo;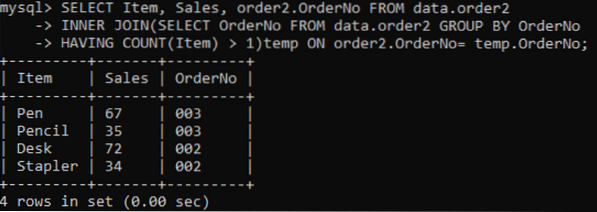
Hledejte duplikáty ve více tabulkách pomocí INNER JOIN
Zde je zjednodušená syntaxe pro hledání duplikátů ve více tabulkách:
>> SELECT col FROM table1 INNER JOIN table2 ON table1.col = tabulka2.col;Zde je popis režijního dotazu:
- col: název sloupců, které mají být zkontrolovány a vybrány.
- VNITŘNÍ SPOJENÍ: funkce použitá ke spojení dvou tabulek.
- NA: slouží ke spojení dvou tabulek podle zadaných sloupců.
V naší databázi máme dvě tabulky „order1“ a „order2“ se sloupcem „OrderNo“, jak je zobrazeno níže.
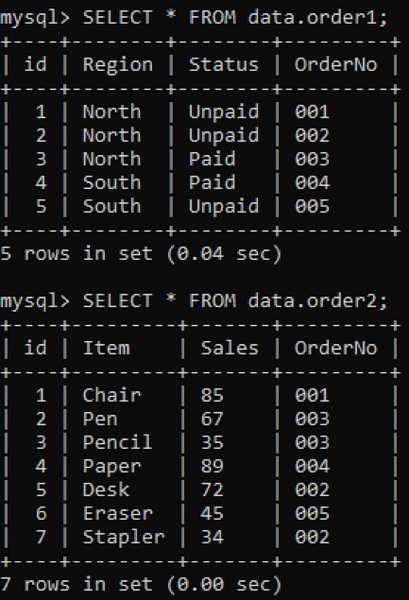
Budeme používat INNER join ke kombinování duplikátů dvou tabulek podle zadaného sloupce. Klauzule INNER JOIN získá všechna data z obou tabulek jejich spojením a klauzule ON se bude týkat sloupců se stejným názvem z obou tabulek, např.G., Objednávka číslo.
>> SELECT * FROM data.order1 INNER JOIN data.order2 ON order1.OrderNo = order2.Objednávka číslo;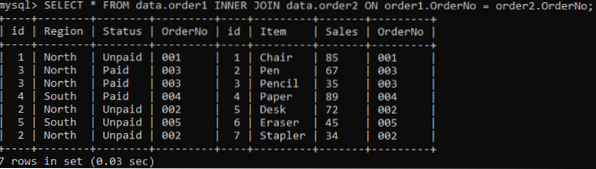
Chcete-li získat konkrétní sloupce ve výstupu, zkuste následující příkaz:
>> VYBERTE Region, Stav, Položka, Prodej FROM data.order1 INNER JOIN data.order2 ON order1.OrderNo = order2.Objednávka číslo;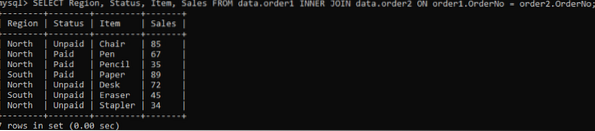
Závěr
Nyní bychom mohli vyhledat více kopií v jedné nebo několika tabulkách informací MySQL a rozpoznat funkci GROUP BY, COUNT a INNER JOIN. Ujistěte se, že jste správně sestavili tabulky a také zda jsou vybrány správné sloupce.


