Pandy pro numerickou analýzu
Pandy byly vyvinuty z potřeby efektivního způsobu správy finančních dat v Pythonu. Pandas je knihovna, kterou lze importovat do pythonu a usnadnit tak manipulaci a transformaci číselných dat. Wes McKinney zahájil projekt v roce 2008. Pandy nyní spravuje skupina inženýrů a podporuje je nezisková organizace NUMFocus, která zajistí její budoucí růst a rozvoj. To znamená, že pandy budou po mnoho let stabilní knihovnou a mohou být zahrnuty do vašich aplikací bez obav z malého projektu.
Ačkoli pandy byly původně vyvinuty pro modelování finančních dat, jejich datové struktury lze použít k manipulaci s různými numerickými daty. Pandas má řadu datových struktur, které jsou integrovány a lze je použít ke snadnému modelování a manipulaci s číselnými daty. Tento výukový program se bude zabývat pandami DataFrame datová struktura do hloubky.
Co je to DataFrame?
A DataFrame je jednou z primárních datových struktur v pandách a představuje 2-D sběr dat. Existuje mnoho analogických objektů k tomuto typu 2-D datové struktury, z nichž některé zahrnují stále oblíbenější tabulku Excel, databázovou tabulku nebo 2-D pole ve většině programovacích jazyků. Níže je uveden příklad a DataFrame v grafickém formátu. Představuje skupinu časových řad závěrečných cen akcií podle data.
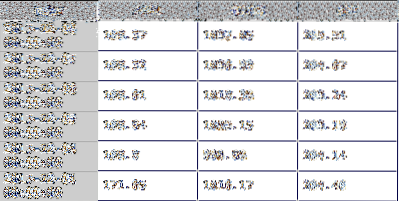
Tento kurz vás provede mnoha metodami datového rámce a k demonstraci těchto funkcí použiji reálný finanční model.
Import dat
Třídy Pandy mají některé zabudované metody, které pomáhají s importem dat do datové struktury. Níže je uveden příklad, jak importovat data do panelu pand pomocí nástroje DataReader třída. Lze jej použít k importu dat z několika bezplatných zdrojů finančních údajů, včetně Quandl, Yahoo Finance a Google. Abyste mohli používat knihovnu pand, musíte ji přidat jako import do svého kódu.
importovat pandy jako pdNíže uvedená metoda spustí program spuštěním metody výukového spuštění.
pokud __name__ == "__main__":tutorial_run ()
The tutorial_run metoda je níže. Je to další metoda, kterou do kódu přidám. První řádek této metody definuje seznam burzovních značek. Tato proměnná bude použita později v kódu jako seznam akcií, pro které budou data požadována za účelem naplnění DataFrame. Druhý řádek kódu volá get_data metoda. Jak uvidíme, get_data metoda bere jako vstup tři parametry. Předáme seznam burzovních cenných papírů, datum zahájení a datum ukončení údajů, které požadujeme.
def tutorial_run ():#Stock Tickers ke zdroji z Yahoo Finance
symboly = ['SPY', 'AAPL', 'GOOG']
#get data
df = get_data (symboly, '2006-01-03', '2017-12-31')
Níže definujeme get_data metoda. Jak jsem zmínil výše, trvá to tři parametry, seznam symbolů, počáteční a konečné datum.
První řádek kódu definuje panel pandy vytvořením instance a DataReader třída. Volání do DataReader třída se připojí k serveru Yahoo Finance a požádá o denní vysoké, nízké, blízké a upravené závěrečné hodnoty pro každou z akcií v symboly seznam. Tato data jsou načtena do objektu panelu pomocí pand.
A panel je 3-D matice a lze ji považovat za „hromádku“ DataFrames. Každý DataFrame v zásobníku obsahuje jednu z denních hodnot požadovaných zásob a období. Například níže DataFrame, výše, je závěrečná cena DataFrame z požadavku. Každý typ ceny (vysoká, nízká, blízká a upravená blízká) má svoji vlastní DataFrame ve výsledném panelu se vrátil z požadavku.
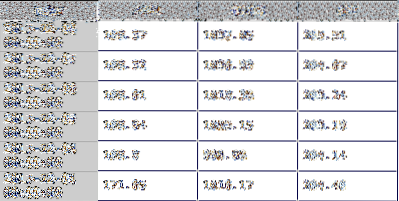
Druhý řádek kódu rozdělí panel na jeden DataFrame a přiřadí výsledná data df. Toto bude moje proměnná pro DataFrame které používám pro zbytek tutoriálu. Uchovává denní uzavírací hodnoty pro tři akcie pro zadané časové období. Panel je rozřezán podle určení, který z panelů DataFrames chtěli byste se vrátit. V tomto příkladu níže uvedeném řádku kódu je to 'Zavřít'.
Jakmile budeme mít naše DataFrame na místě se budu zabývat některými užitečnými funkcemi v knihovně pandas, které nám umožní manipulovat s daty v DataFrame objekt.
def get_data (symboly, start_date, end_date):panel = data.DataReader (symboly, 'yahoo', start_date, end_date)
df = panel ['Zavřít']
tisk (srov.hlava (5))
tisk (srov.ocas (5))
návrat df
Hlavy a ocasy
Třetí a čtvrtý řádek get_data vytiskněte funkční hlavu a konec datového rámce. Považuji to za nejužitečnější při ladění a vizualizaci dat, ale lze jej také použít k výběru prvního nebo posledního vzorku dat v DataFrame. Funkce hlavy a ocasu vytahuje první a poslední řádek dat z DataFrame. Parametr integer mezi závorkami definuje počet řádků, které mají být metodou vybrány.
.loc
The DataFrame loc metoda plátky DataFrame podle indexu. Níže uvedený řádek kódu plátky df DataFrame podle indexu 2017-12-12. Níže jsem poskytl snímek obrazovky s výsledky.
tisk df.loc ["12.12.2017"]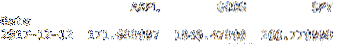
loc lze použít také jako dvourozměrný řez. První parametr je řádek a druhý parametr je sloupec. Níže uvedený kód vrací jednu hodnotu, která se rovná závěrečné ceně Apple 12. 12. 2014.
tisk df.loc ["12.12.2017", "AAPL"]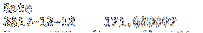
The loc metodu lze použít k rozdělení všech řádků ve sloupci nebo všech sloupců v řádku. The : operátor se používá k označení všech. Níže uvedený řádek kódu vybírá všechny řádky ve sloupci pro zavírací ceny Google.
tisk df.loc [:, "GOOG"]
.fillna
Je běžné, zejména v souborech finančních údajů, mít v sobě hodnoty NaN DataFrame. Pandas poskytuje funkci k vyplnění těchto hodnot číselnou hodnotou. To je užitečné, pokud si přejete provést nějaký výpočet na datech, která mohou být zkosená nebo selhat kvůli hodnotám NaN.
The .fillna metoda nahradí zadanou hodnotu za každou hodnotu NaN ve vaší datové sadě. Níže uvedený řádek kódu vyplní veškerý NaN v našem DataFrame s 0. Tuto výchozí hodnotu lze změnit pro hodnotu, která splňuje potřebu datové sady, se kterou pracujete, aktualizací parametru, který je předán metodě.
df.fillna (0)Normalizace dat
Při použití algoritmů strojového učení nebo finanční analýzy je často užitečné normalizovat vaše hodnoty. Níže uvedená metoda představuje efektivní výpočet pro normalizaci dat v pandách DataFrame. Doporučuji vám použít tuto metodu, protože tento kód poběží efektivněji než jiné metody normalizace a může ukázat velké zvýšení výkonu u velkých datových sad.
.iloc je metoda podobná .loc ale bere spíše parametry založené na poloze než parametry založené na značce. Trvá index založený na nule, nikoli název sloupce z .loc příklad. Níže uvedený normalizační kód je příkladem některých výkonných maticových výpočtů, které lze provést. Přeskočím lekci lineární algebry, ale v podstatě tento řádek kódu rozdělí celou matici nebo DataFrame o první hodnotu každé časové řady. V závislosti na vaší datové sadě můžete potřebovat normu založenou na min, max nebo střední hodnotě. Tyto normy lze také snadno vypočítat pomocí níže uvedeného stylu založeného na matici.
def normalize_data (df):vrátit df / df.iloc [0 ,:]
Vynesení dat
Při práci s daty je často nutné je graficky znázornit. Metoda vykreslení umožňuje snadno sestavit graf z vašich datových sad.
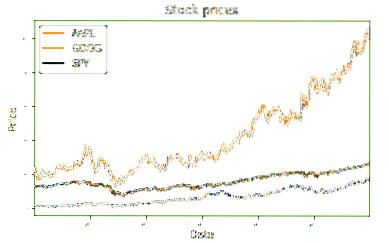
Níže uvedená metoda má naši DataFrame a vykreslí jej na standardní spojnicový graf. Metoda trvá a DataFrame a název jako jeho parametry. První řádek kódových sad sekera na spiknutí DataFrame df. Nastavuje nadpis a velikost písma pro text. Následující dva řádky nastavují popisky pro osu x a y. Poslední řádek kódu volá metodu show, která vytiskne graf na konzolu. Níže poskytuji snímek obrazovky s výsledky z grafu. To představuje normalizované uzavírací ceny pro každou z akcií za vybrané časové období.
def plot_data (df, title = "Ceny akcií"):ax = df.zápletka (název = název, velikost písma = 2)
sekera.set_xlabel ("Datum")
sekera.set_ylabel ("Cena")
spiknutí.ukázat()
Pandas je robustní knihovna pro manipulaci s daty. Může být použit pro různé typy dat a představuje stručnou a efektivní sadu metod pro manipulaci s vaší datovou sadou. Níže jsem poskytl celý kód z tutoriálu, abyste jej mohli zkontrolovat a změnit podle svých potřeb. Existuje několik dalších metod, které vám pomohou s manipulací s daty, a doporučuji vám zkontrolovat dokumenty pandy zveřejněné na níže uvedených referenčních stránkách. NumPy a MatPlotLib jsou další dvě knihovny, které fungují dobře pro datovou vědu a lze je použít ke zlepšení výkonu knihovny pand.
Celý kód
importovat pandy jako pddef plot_selected (df, sloupce, start_index, end_index):
plot_data (srov.ix [start_index: end_index, sloupce])
def get_data (symboly, start_date, end_date):
panel = data.DataReader (symboly, 'yahoo', start_date, end_date)
df = panel ['Zavřít']
tisk (srov.hlava (5))
tisk (srov.ocas (5))
tisk df.loc ["12.12.2017"]
tisk df.loc ["12.12.2017", "AAPL"]
tisk df.loc [:, "GOOG"]
df.fillna (0)
návrat df
def normalize_data (df):
vrátit df / df.ix [0 ,:]
def plot_data (df, title = "Ceny akcií"):
ax = df.zápletka (název = název, velikost písma = 2)
sekera.set_xlabel ("Datum")
sekera.set_ylabel ("Cena")
spiknutí.ukázat()
def tutorial_run ():
# Vyberte symboly
symboly = ['SPY', 'AAPL', 'GOOG']
#get data
df = get_data (symboly, '2006-01-03', '2017-12-31')
plot_data (df)
pokud __name__ == "__main__":
tutorial_run ()
Reference
Domovská stránka Pandy
Stránka Wikipedia Pandas
https: // en.wikipedia.org / wiki / Wes_McKinney
Domovská stránka NumFocus


