Abyste pochopili koncept fulltextového vyhledávání, musíte si vybavit znalosti vyhledávání vzorů pomocí klíčového slova LIKE. Předpokládejme tedy tabulku „osoba“ v databázi „test“ s následujícími záznamy.
>> VYBRAT * OD osoby;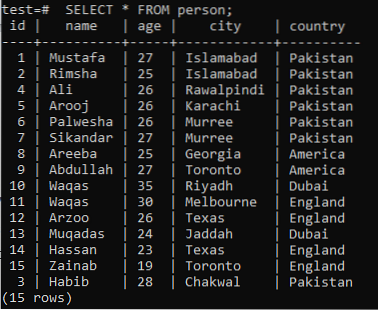
Předpokládejme, že chcete načíst záznamy této tabulky, kde sloupec „name“ má v každé ze svých hodnot znak „i“. Při použití klauzule LIKE v příkazovém prostředí vyzkoušejte níže uvedený dotaz SELECT. Z níže uvedeného výstupu vidíte, že pro tento konkrétní znak „i“ máme ve sloupci „name“ pouze 5 záznamů.
>> VYBRAT * OD osoby, KDE jméno jako '% i%';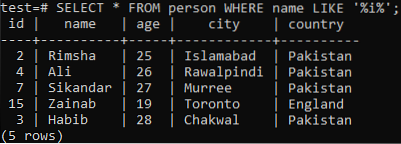
Použití Tvsector:
Někdy není užitečné použít klíčové slovo LIKE k rychlému vyhledávání vzoru, i když to slovo tam je. Možná byste uvažovali o použití standardních výrazů, a přestože se jedná o proveditelnou alternativu, regulární výrazy jsou silné i pomalé. Mít procedurální vektor pro celá slova v textu, lidový popis těchto slov, je mnohem efektivnější způsob řešení tohoto problému. Abychom na něj mohli reagovat, byl vytvořen koncept kompletního textového vyhledávání a datového typu tsvector. V PostgreSQL existují dvě metody, které dělají přesně to, co chceme:
- To_tvsector: Slouží k vytvoření seznamu tokenů (ts znamená pro „textové vyhledávání“).
- To_tsquery: Slouží k hledání vektoru pro výskyt konkrétních výrazů nebo frází.
Příklad 01:
Začněme jednoduchým příkladem vytvoření vektoru. Předpokládejme, že chcete pro řetězec vytvořit vektor: „Někteří lidé mají kudrnaté hnědé vlasy správným kartáčováním.“. Takže musíte psát funkci to_tvsector () spolu s touto větou v závorkách dotazu SELECT, jak je uvedeno níže. Z níže uvedeného výstupu můžete vidět, že by přinesl vektor odkazů (pozic souborů) pro každý token a také tam, kde jsou úmyslně ignorovány výrazy s malým kontextem, jako jsou články () a spojky (a, nebo).
>> SELECT to_tsvector ('Někteří lidé mají kudrnaté hnědé vlasy správným kartáčováním');
Příklad 02:
Předpokládejme, že máte dva dokumenty s některými údaji v obou z nich. K uložení těchto dat nyní použijeme skutečný příklad generování tokenů. Předpokládejme, že jste vytvořili tabulku „Data“ ve své databázi „test“ s některými sloupci v ní pomocí níže uvedeného dotazu CREATE TABLE. Nezapomeňte v něm vytvořit sloupec typu TVSECTOR s názvem „token“. Z níže uvedeného výstupu se můžete podívat na vytvořenou tabulku.
>> CREATE TABLE Data (Id SERIAL PRIMARY KEY, info TEXT, token TSVECTOR);
Nyní je na nás, abychom přidali celková data obou dokumentů v této tabulce. Zkuste tedy níže uvedený příkaz INSERT v prostředí příkazového řádku. Nakonec byly záznamy z obou dokumentů úspěšně přidány do tabulky „Data“.
>> INSERT INTO Data (info) VALUES („Dvě křivdy nikdy nemohou napravit jednu.'), („Je to ten, kdo může hrát fotbal.'), (' Mohu v tom hrát roli?'), (' Bolest uvnitř jednoho nelze pochopit '), (' Přineste do svého života broskev);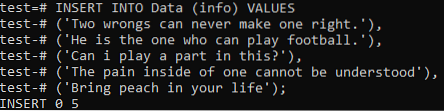
Nyní musíte kolonizovat sloupec tokenů obou dokumentů s jejich konkrétním vektorem. Nakonec jednoduchý dotaz UPDATE vyplní sloupec tokenů odpovídajícím vektorem pro každý soubor. Chcete-li tak učinit, musíte v příkazovém shellu provést níže uvedený dotaz. Výstup ukazuje, že aktualizace byla konečně provedena.
>> UPDATE Data f1 SET token = to_tsvector (f1.info) FROM Data f2;
Nyní, když máme vše na svém místě, se vraťme k naší ilustraci „umíme“ skenováním. To_tsquery s operátorem AND, jak již bylo řečeno, nedělá žádný rozdíl mezi umístěním souborů v souborech, jak je ukázáno z výstupu uvedeného níže.
>> SELECT Id, info FROM Data WHERE token @@ to_tsquery ('can & one');
Příklad 04:
Abychom našli slova, která jsou „vedle sebe“, zkusíme stejný dotaz s '<->operátor. Změna se zobrazí na výstupu níže.
>> SELECT Id, info FROM Data WHERE token @@ to_tsquery ('can <-> jeden');
Zde je příklad bezprostředního slova vedle jiného.
>> SELECT Id, info FROM Data WHERE token @@ to_tsquery ('one <-> bolest');
Příklad 05:
Slova, která nejsou bezprostředně vedle sebe, najdeme pomocí čísla v operátoru vzdálenosti k referenční vzdálenosti. Blízkost mezi „přinést“ a „životem“ je od zobrazeného obrázku 4 slova.
>> SELECT * FROM Data WHERE token @@ to_tsquery ('bring <4> život');
Níže je přiložena kontrola blízkosti slov pro téměř 5 slov.
>> SELECT * FROM Data WHERE token @@ to_tsquery ('špatně <5> že jo');
Závěr:
Nakonec jste provedli všechny jednoduché a komplikované příklady fulltextového vyhledávání pomocí operátorů a funkcí To_tvsector a to_tsquery.


