- Pro přeformátování zdrojového kódu
- Pro vyčištění dat
- Pro zjednodušení výstupu z příkazového řádku
Pokud mluvíme o předních bílých prostorech, lze je snadno zjistit tak, jak jsou na začátku textu. Není však snadné rozpoznat koncové mezery. Totéž platí pro dvojité mezery, které je také někdy obtížné zjistit. Všechno se stává náročnějším, když potřebujete odstranit všechny ty úvodní a koncové mezery z dokumentu obsahujícího tisíce řádků.
Chcete-li z dokumentu odstranit prázdné znaky, můžete použít různé nástroje, jako jsou awk, sed, cut a tr. V některých dalších článcích jsme diskutovali o použití awk při odstraňování mezer. V tomto článku budeme diskutovat o použití sedu k odstranění mezer z dat.
Naučíte se používat sed k:
- Odstraňte všechna bílá místa
- Odstraňte přední mezery
- Odstraňte koncové mezery
- Odstraňte úvodní i koncové mezery
- Nahraďte více mezer jedním prostorem
Budeme spouštět příkazy na Ubuntu 20.04 Focal Fossa. Stejné příkazy můžete spustit také na jiných distribucích Linuxu. Ke spouštění příkazů použijeme výchozí aplikaci Terminál Ubuntu. Terminál otevřete pomocí klávesové zkratky Ctrl + Alt + T.
Co je Sed
Sed (zkratka pro editor streamů) je velmi výkonný a praktický nástroj v Linuxu, který nám umožňuje provádět základní manipulace s textem na vstupních streamech. Není to textový editor, ale pomáhá manipulovat a filtrovat text. Přijímá vstupní toky a upravuje je podle pokynů uživatele a poté vytiskne transformovaný text na obrazovku.
Se sed můžete:
- Vyberte text
- Hledat text
- Vložte text
- Nahradit text
- Smazat text
Odstranění mezer pomocí Sed
K odstranění mezer z textu použijeme následující syntaxi:
s / REGEXP / nahrazení / příznakyKde
- s /: je substituční výraz
- REGEXP: je regulární výraz, který má odpovídat
- výměna, nahrazení: je náhradní řetězec
- vlajky: Příznak „g“ použijeme pouze k globálnímu nahrazení na každém řádku
Regulární výrazy
Některé z regulárních výrazů, které zde použijeme, jsou:
- ^ odpovídá začátku řádku
- $ zápasy konec řádku
- + odpovídá jednomu nebo více výskytům předchozího znaku
- * odpovídá nule nebo více výskytům předchozího znaku.
Pro demonstrační účely použijeme následující ukázkový soubor s názvem „testfile“.
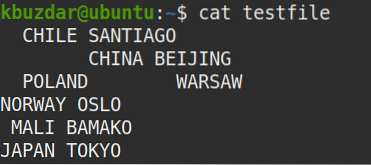
Zobrazit všechny mezery v souboru
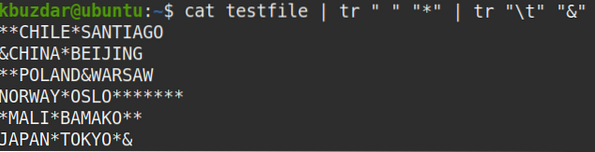
Chcete-li najít všechny mezery ve vašem souboru, přepněte výstup příkazu cat do příkazu tr takto:
$ kočičí testovací soubor | tr "" "*" | tr "\ t" "&"Tento příkaz nahradí všechny mezery ve vašem souboru symbolem (*), což usnadňuje vyhledání všech mezer bez ohledu na to, zda jsou jednotlivé, více, přední nebo koncové mezery.
Na následujícím snímku obrazovky vidíte, že mezery jsou nahrazeny symbolem *.
Odebrat všechny mezery (včetně mezer a karet)
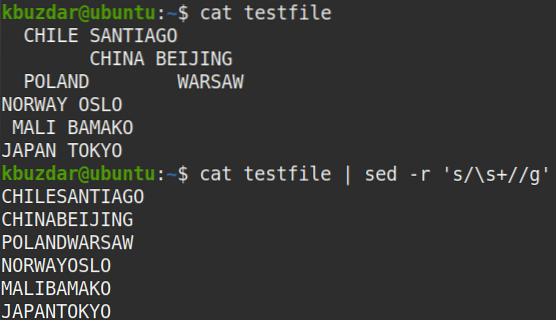
V některých případech musíte z dat odstranit všechny mezery, tj.E. úvodní, koncové a mezery mezi texty. Následující příkaz odstraní všechny mezery z „testovacího souboru“.
$ kočičí testovací soubor | sed -r 's / \ s + // g'Poznámka: Sed nezmění vaše soubory, pokud do souboru neuložíte výstup.
Výstup:
Po spuštění výše uvedeného příkazu se objevil následující výstup, který ukazuje, že z textu byly odstraněny všechny mezery.
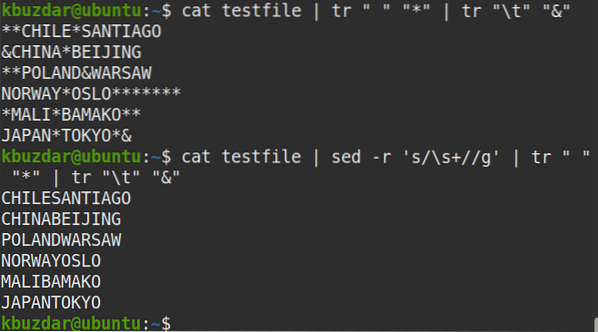
Následující příkaz můžete také použít k ověření, že byly odstraněny všechny prázdné znaky.
$ kočičí testovací soubor | sed -r 's / \ s + // g' | tr "" "*" | tr "\ t" "&"Z výstupu vidíte, že neexistuje žádný symbol (*), což znamená, že byly odstraněny všechny prázdné znaky.
Chcete-li odstranit všechny prázdné znaky, ale pouze z konkrétního řádku (řekněme řádek číslo 2), můžete použít následující příkaz:
$ kočičí testovací soubor | sed -r '2s / \ s + // g'Odebrat všechny přední mezery (včetně mezer a karet)
Chcete-li odstranit všechny prázdné znaky od začátku každého řádku (úvodní prázdné znaky), použijte následující příkaz:
$ kočičí testovací soubor | sed 's / ^ [\ t] * //'Výstup:
Následující výstup se objevil po spuštění výše uvedeného příkazu, který ukazuje, že z textu byly odstraněny všechny mezery v mezerách.
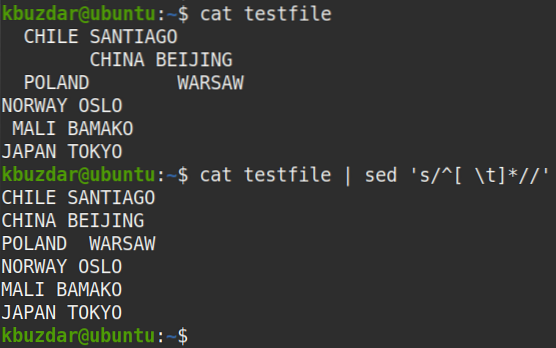
Pomocí následujícího příkazu můžete také ověřit, že byly odstraněny všechny mezery mezi předními znaky:
$ kočičí testovací soubor | sed 's / ^ [\ t] * //' | tr "" "*" | tr "\ t" "&"Z výstupu vidíte, že na začátku řádků není žádný symbol (*), který ověřuje, že jsou odstraněny všechny mezery v mezerách.
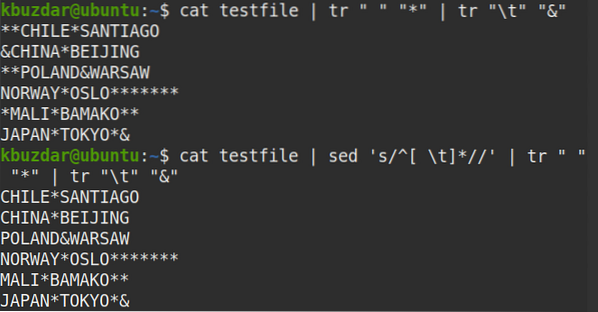
Chcete-li odstranit úvodní prázdné znaky pouze z konkrétního řádku (řekněme řádek číslo 2), můžete použít následující příkaz:
$ kočičí testovací soubor | sed '2s / ^ [\ t] * //'Odebrat všechny koncové mezery (včetně mezer a karet)
Chcete-li odstranit všechny mezery na konci každého řádku (koncové mezery), použijte následující příkaz:
$ kočičí testovací soubor | sed 's / [\ t] * $ //'Výstup:
Následující výstup se objevil po spuštění výše uvedeného příkazu, který ukazuje, že z textu byly odstraněny všechny koncové mezery.
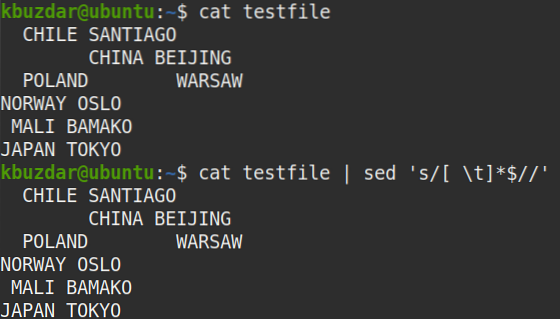
Následující příkaz můžete také použít k ověření, že byly odstraněny všechny koncové mezery.
$ kočičí testovací soubor | sed 's / [\ t] * $ //' | tr "" "*" | tr "\ t" "&"Z výstupu vidíte, že na konci řádků není žádný symbol (*), který ověřuje, že jsou odstraněny všechny koncové mezery.
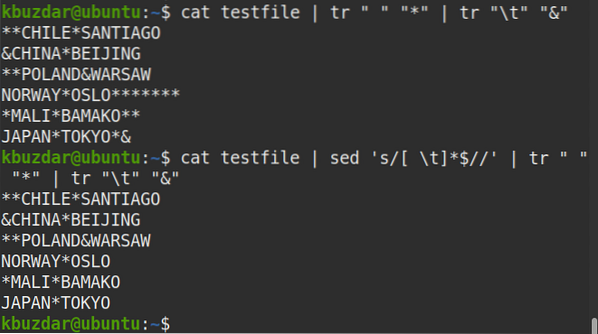
Chcete-li odstranit koncové mezery pouze z konkrétního řádku (řekněme řádek číslo 2), můžete použít následující příkaz:
$ kočičí testovací soubor | sed '2s / [\ t] * $ //'Odstraňte přední i koncové mezery
Odebrání všech mezer na začátku i na konci každého řádku (tj.E. úvodní i koncové mezery), použijte následující příkaz:
$ kočičí testovací soubor | sed 's / ^ [\ t] * //; s / [\ t] * $ //'Výstup:
Po spuštění výše uvedeného příkazu se objevil následující výstup, který ukazuje, že jak úvodní, tak i koncové mezery byly z textu odstraněny.
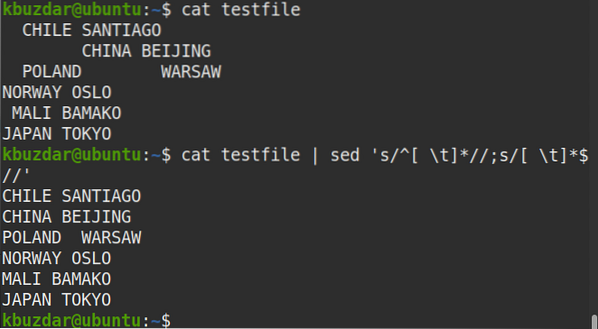
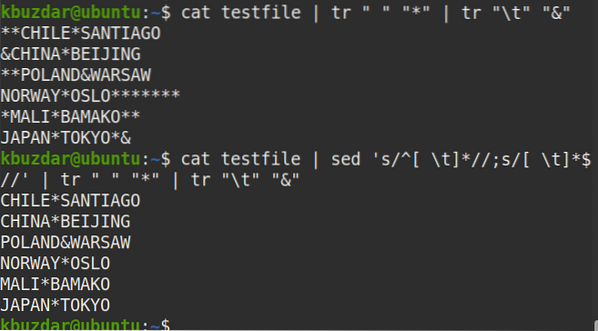
Pomocí následujícího příkazu můžete také ověřit, že byly odstraněny jak úvodní, tak i koncové mezery.
$ kočičí testovací soubor | sed 's / ^ [\ t] * //; s / [\ t] * $ //' | tr "" "*" | tr "\ t" "&"Z výstupu vidíte, že na začátku nebo na konci řádků není žádný symbol (*), který ověřuje, že jsou odstraněny všechny mezery mezi předními a zadními mezerami.
Chcete-li odstranit úvodní i koncové mezery pouze z určitého řádku (řekněme řádek číslo 2), můžete použít následující příkaz:
$ kočičí testovací soubor | sed '2s / ^ [\ t] * //; 2s / [\ t] * $ //'Nahraďte více mezer jednoduchými mezerami
V některých případech je v souboru více mezer na stejném místě, ale potřebujete pouze jedno prázdné místo. Můžete tak učinit nahrazením těchto více mezer jedním prostorem pomocí sed.
Následující příkaz nahradí všech více mezer jedním prázdným znakem z každého řádku v „testovacím souboru“.
$ kočičí testovací soubor | sed 's / [] \ + / / g'Výstup:
Následující výstup se objevil po spuštění výše uvedeného příkazu, který ukazuje, že více mezer bylo nahrazeno jedním mezerami.
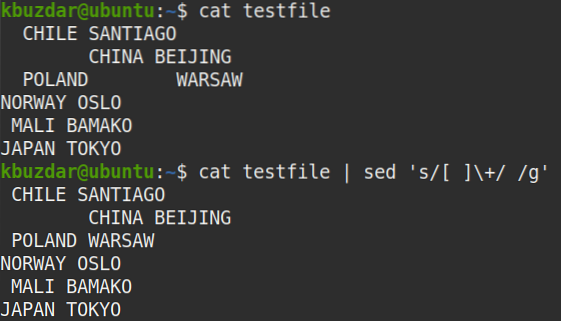
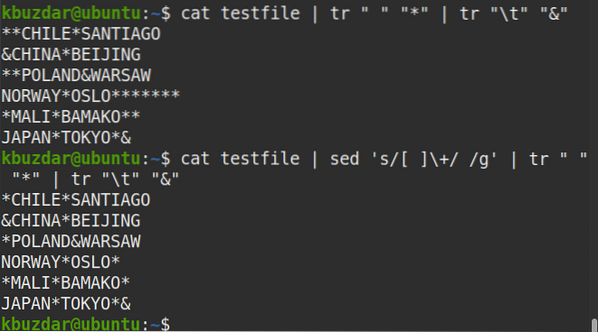
Následující příkaz můžete také použít k ověření, zda je více mezer nahrazeno jedním mezerami:
$ kočičí testovací soubor | sed 's / [] \ + / / g' | tr "" "*" | tr "\ t" "&"Z výstupu vidíte na každém místě jeden symbol (*), který ověří, že všechny výskyty více mezer jsou nahrazeny jedním mezerou.
Takže šlo o odstranění mezer z vašich dat pomocí sed. V tomto článku jste se naučili, jak používat sed k odstranění všech mezer z vašich dat, odebrání pouze úvodního nebo koncového mezery a odebrání úvodního i koncového mezery. Také jste se naučili, jak nahradit více prostorů jedním prostorem. Nyní bude pro vás snadné odstranit prázdné znaky ze souboru obsahujícího stovky nebo tisíce řádků.


