
Téměř všichni začínající datoví vědci a vývojáři strojového učení jsou zmateni výběrem programovacího jazyka. Vždy se ptají, který programovací jazyk bude pro jejich projekt strojového učení a datové vědy nejlepší. Buď půjdeme na python, R nebo MatLab. Volba programovacího jazyka závisí na preferencích vývojářů a systémových požadavcích. Mezi dalšími programovacími jazyky je R jedním z nejpotenciálnějších a nejkrásnějších programovacích jazyků, které mají několik balíčků strojového učení R pro ML, AI a datové vědecké projekty.
V důsledku toho lze pomocí těchto balíčků strojového učení R snadno a efektivně rozvíjet svůj projekt. Podle průzkumu Kaggle je R jedním z nejpopulárnějších jazyků strojového učení s otevřeným zdrojovým kódem.
Nejlepší balíčky strojového učení R
R je jazyk s otevřeným zdrojovým kódem, takže lidé mohou přispívat odkudkoli na světě. Ve svém kódu můžete použít černou skříňku, kterou napsal někdo jiný. V R je tato černá skříňka označována jako balíček. Balíček není nic jiného než předem napsaný kód, který může kdokoli opakovaně používat. Níže uvádíme 20 nejlepších balíčků strojového učení R.
1. STRÁŽEK
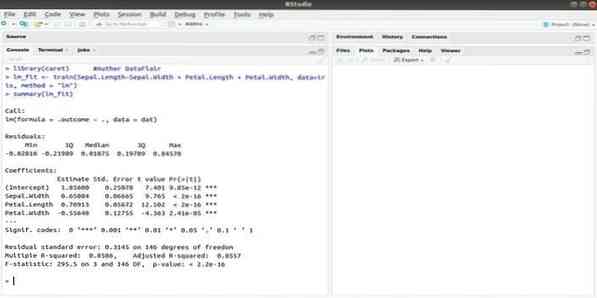 Balíček CARET se týká klasifikace a regresního tréninku. Úkolem tohoto balíčku CARET je integrovat školení a predikci modelu. Je to jeden z nejlepších balíčků R pro strojové učení i vědu o datech.
Balíček CARET se týká klasifikace a regresního tréninku. Úkolem tohoto balíčku CARET je integrovat školení a predikci modelu. Je to jeden z nejlepších balíčků R pro strojové učení i vědu o datech.
Parametry lze prohledávat integrací několika funkcí pro výpočet celkového výkonu daného modelu pomocí metody prohledávání mřížky tohoto balíčku. Po úspěšném dokončení všech pokusů konečně vyhledá mřížka nejlepší kombinace.
Po instalaci tohoto balíčku může vývojář spustit názvy (getModelInfo ()) a zobrazit 217 možných funkcí, které lze spustit pouze pomocí jedné funkce. Pro sestavení prediktivního modelu používá balíček CARET funkci train (). Syntaxe této funkce:
vlak (vzorec, data, metoda)
Dokumentace
2. randomForest
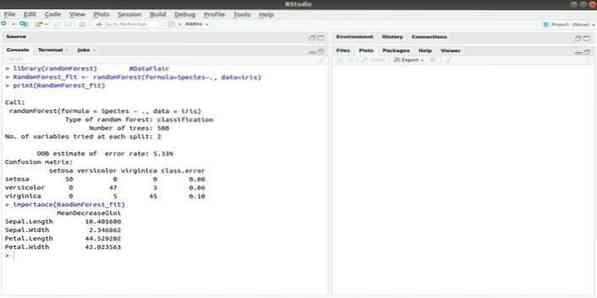
RandomForest je jedním z nejpopulárnějších balíčků R pro strojové učení. Tento balíček strojového učení R lze použít k řešení regresních a klasifikačních úloh. Navíc jej lze použít k trénování chybějících hodnot a odlehlých hodnot.
Tento balíček strojového učení s R se obecně používá ke generování více čísel rozhodovacích stromů. V zásadě to vyžaduje náhodné vzorky. A pak jsou pozorování dána do rozhodovacího stromu. Společný výstup, který pochází z rozhodovacího stromu, je konečným výstupem. Syntaxe této funkce:
randomForest (vzorec =, data =)
Dokumentace
3. e1071
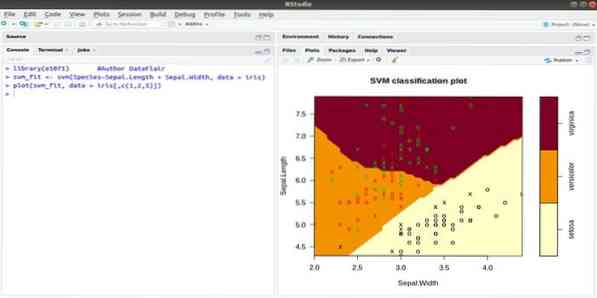
Tento e1071 je jedním z nejpoužívanějších balíčků R pro strojové učení. Pomocí tohoto balíčku může vývojář implementovat podpůrné vektorové stroje (SVM), výpočet nejkratší cesty, pytlované shlukování, klasifikátor Naive Bayes, krátkodobou Fourierovu transformaci, fuzzy shlukování atd.
Například pro data IRIS je syntaxe SVM:
svm (Druh ~ Sepal.Délka + Sepal.Šířka, data = clona)
Dokumentace
4. Rpart
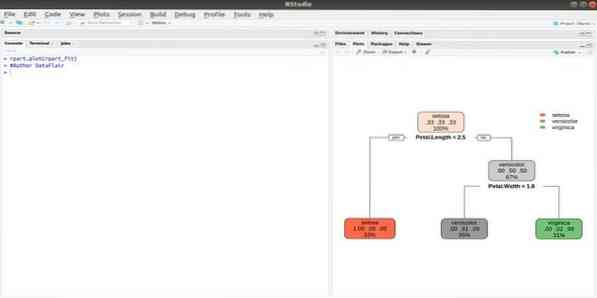
Rpart znamená rekurzivní dělení a regresní trénink. Tento balíček R pro strojové učení lze provádět jak úkoly, tak klasifikací a regresí. Působí pomocí dvoustupňového kroku. Výstupní model binárního stromu. Funkce plot () se používá k vykreslení výsledku výstupu. Existuje také alternativní funkce prp (), která je flexibilnější a výkonnější než základní funkce plot ().
Funkce rpart () slouží k navázání vztahu mezi nezávislými a závislými proměnnými. Syntaxe je:
rpart (vzorec, data =, metoda =, kontrola =)
kde vzorec je kombinací nezávislých a závislých proměnných, data je název datové sady, metoda je cílem a kontrola je váš systémový požadavek.
Dokumentace
5. KernLab
Pokud chcete svůj projekt vyvíjet na základě algoritmů strojového učení založených na jádře, můžete tento balíček R použít pro strojové učení. Tento balíček se používá pro SVM, analýzu funkcí jádra, algoritmus hodnocení, primitiva dot produktu, Gaussian proces a mnoho dalších. KernLab je široce používán pro implementace SVM.
K dispozici jsou různé funkce jádra. Zde jsou uvedeny některé funkce jádra: polydot (funkce polynomiálního jádra), tanhdot (funkce hyperbolického tangenta jádra), laplacedot (funkce laplaciánského jádra) atd. Tyto funkce se používají k provádění problémů s rozpoznáváním vzorů. Uživatelé však mohou používat své funkce jádra namísto předdefinovaných funkcí jádra.
Dokumentace
6. síť
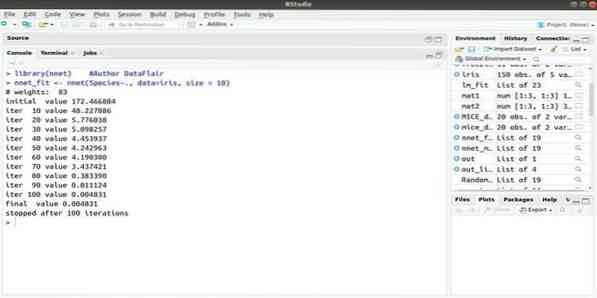 Pokud chcete vyvinout svou aplikaci pro strojové učení pomocí umělé neurální sítě (ANN), může vám tento balíček nnet pomoci. Je to jeden z nejpopulárnějších a nejjednodušších implementací balíčku neuronových sítí. Ale je to omezení, že je to jedna vrstva uzlů.
Pokud chcete vyvinout svou aplikaci pro strojové učení pomocí umělé neurální sítě (ANN), může vám tento balíček nnet pomoci. Je to jeden z nejpopulárnějších a nejjednodušších implementací balíčku neuronových sítí. Ale je to omezení, že je to jedna vrstva uzlů.
Syntaxe tohoto balíčku je:
nnet (vzorec, data, velikost)
Dokumentace
7. dplyr
Jeden z nejpoužívanějších balíčků R pro datovou vědu. Poskytuje také některé snadno použitelné, rychlé a konzistentní funkce pro manipulaci s daty. Hadley Wickham píše tento programovací balíček r pro vědu o datech. Tento balíček se skládá ze sady sloves i.E., mutovat (), vybrat (), filtrovat (), shrnout () a uspořádat ().
Chcete-li nainstalovat tento balíček, musíte napsat tento kód:
Nainstalujte.balíčky („dplyr“)
Chcete-li načíst tento balíček, musíte napsat tuto syntaxi:
knihovna (dplyr)
Dokumentace
8. ggplot2
Dalším z nejelegantnějších a nejestetičtějších grafických balíčků R pro datovou vědu je ggplot2. Je to systém vytváření grafiky založený na gramatice grafiky. Syntaxe instalace pro tento balíček datových věd je:
Nainstalujte.balíčky („ggplot2“)
Dokumentace
9. Wordcloud

Pokud se jeden obrázek skládá z tisíců slov, nazývá se Wordcloud. V zásadě se jedná o vizualizaci textových dat. Tento balíček strojového učení využívající R se používá k vytvoření reprezentace slov a vývojář může přizpůsobit Wordcloud podle svých preferencí, jako je uspořádání slov náhodně nebo stejných frekvenčních slov společně nebo vysokofrekvenčních slov ve středu atd.
V jazyce strojového učení R jsou k vytvoření wordcloudu k dispozici dvě knihovny: Wordcloud a Worldcloud2. Zde si ukážeme syntaxi pro WordCloud2. Chcete-li nainstalovat WordCloud2, musíte napsat:
1. vyžadují (devtools)
2. install_github („lchiffon / wordcloud2“)
Nebo jej můžete použít přímo:
knihovna (wordcloud2)
Dokumentace
10. tidyr
Dalším široce používaným balíčkem r pro datovou vědu je tidyr. Cílem tohoto r programování pro vědu o datech je uklízení dat. V pořádku je proměnná umístěna do sloupce, pozorování je umístěno do řádku a hodnota je v buňce. Tento balíček popisuje standardní způsob řazení dat.
Pro instalaci můžete použít tento fragment kódu:
Nainstalujte.balíčky („tidyr“)
Pro načítání je kód:
knihovna (tidyr)
Dokumentace
11. lesklý
Balíček R, Shiny, je jedním z rámců webových aplikací pro datovou vědu. Pomáhá bez námahy vytvářet webové aplikace z R. Vývojář může nainstalovat software na každý klientský systém nebo hostitele kabiny webové stránky. Vývojář také může vytvářet řídicí panely nebo je může vložit do dokumentů R Markdown.
Lesklé aplikace lze navíc rozšířit o různé skriptovací jazyky, jako jsou html widgety, motivy CSS a akce JavaScriptu. Jedním slovem můžeme říci, že tento balíček je kombinací výpočetní síly R s interaktivitou moderního webu.
Dokumentace
12. tm
Není třeba říkat, že těžba textu je dnes objevující se aplikací strojového učení. Tento balíček strojového učení R poskytuje rámec pro řešení úloh těžby textu. V aplikaci pro dolování textu, tj.E., analýza sentimentu nebo klasifikace zpráv, vývojář má různé typy zdlouhavé práce, jako je odstraňování nežádoucích a irelevantních slov, odstraňování interpunkčních znamének, odstraňování stop slov a mnoho dalších.
Balíček tm obsahuje několik flexibilních funkcí, které vám usnadní práci, jako je removeNumbers (): odebrání čísel z daného textového dokumentu, weightTfIdf (): pro termín Frekvence a inverzní frekvence dokumentu, tm_reduce (): kombinace transformací, removePunctuation () na odstranit interpunkční znaménka z daného textového dokumentu a mnoha dalších.
Dokumentace
13. Balíček MICE
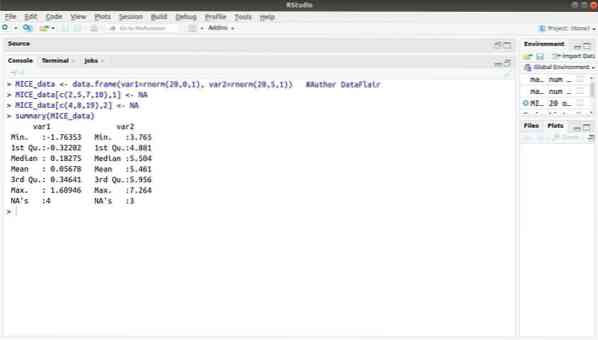
Balíček strojového učení s R, MICE odkazuje na vícerozměrnou imputaci prostřednictvím řetězových sekvencí. Vývojář projektu téměř po celou dobu čelí běžnému problému s datovou sadou strojového učení, což je chybějící hodnota. Tento balíček lze použít k imputaci chybějících hodnot pomocí několika technik.
Tento balíček obsahuje několik funkcí, jako je kontrola chybějících datových vzorů, diagnostika kvality imputovaných hodnot, analýza dokončených datových sad, ukládání a export imputovaných dat v různých formátech a mnoho dalších.
Dokumentace
14. igraf
Balíček síťové analýzy, igraph, je jedním z výkonných balíčků R pro datovou vědu. Je to kolekce výkonných, efektivních, snadno použitelných a přenosných nástrojů pro síťovou analýzu. Tento balíček je také otevřený a zdarma. Kromě toho lze program igraphn naprogramovat na Python, C / C ++ a Mathematica.
Tento balíček má několik funkcí pro generování náhodných a pravidelných grafů, vizualizace grafu atd. S tímto velkým balíčkem můžete také pracovat s velkým grafem. Existuje několik požadavků k použití tohoto balíčku: pro Linux je zapotřebí kompilátor C a C ++.
Instalace tohoto programovacího balíčku R pro datovou vědu je:
Nainstalujte.balíčky („igraf“)
Pro načtení tohoto balíčku musíte napsat:
knihovna (igraf)
Dokumentace
15. ROCR
Balíček R pro datovou vědu, ROCR, se používá k vizualizaci výkonu bodovacích klasifikátorů. Tento balíček je flexibilní a snadno se používá. Pro volitelné parametry jsou potřeba pouze tři příkazy a výchozí hodnoty. Tento balíček se používá k vývoji mezních parametrických křivek parametrů s mezními hodnotami. V tomto balíčku existuje několik funkcí, jako je prediction (), které se používají k vytváření predikčních objektů, performance () používaných k vytváření výkonových objektů atd.
Dokumentace
16. DataExplorer
Balíček DataExplorer je jedním z nejrozsáhleji snadno použitelných balíčků R pro datovou vědu. Mezi četnými úkoly v oblasti datové vědy je jednou z nich průzkumná analýza dat (EDA). Při průzkumné analýze dat musí datový analytik věnovat datům větší pozornost. Není snadné zkontrolovat nebo zpracovat data ručně nebo použít špatné kódování. Je nutná automatizace analýzy dat.
Tento balíček R pro datovou vědu poskytuje automatizaci průzkumu dat. Tento balíček slouží ke skenování a analýze jednotlivých proměnných a jejich vizualizaci. Je to užitečné, když je datová sada obrovská. Analýza dat tak může efektivně a bez námahy extrahovat skryté znalosti dat.
Balíček lze nainstalovat z CRANu přímo pomocí níže uvedeného kódu:
Nainstalujte.balíčky („DataExplorer“)
Chcete-li načíst tento balíček R, musíte napsat:
knihovna (DataExplorer)
Dokumentace
17. mlr
Jedním z nejneuvěřitelnějších balíčků strojového učení R je balíček mlr. Tento balíček je šifrování několika úloh strojového učení. To znamená, že můžete provést několik úkolů pouze pomocí jediného balíčku a pro tři různé úkoly není nutné používat tři balíčky.
Balíček mlr je rozhraní pro četné klasifikační a regresní techniky. Mezi techniky patří strojově čitelné popisy parametrů, shlukování, generické opětovné vzorkování, filtrování, extrakce funkcí a mnoho dalších. Lze také provádět paralelní operace.
Pro instalaci musíte použít následující kód:
Nainstalujte.balíčky („mlr“)
Načtení tohoto balíčku:
knihovna (mlr)
Dokumentace
18. arules
Balíček, arules (pravidla asociace těžby a časté položky), je široce používaný balíček R strojového učení. Pomocí tohoto balíčku lze provést několik operací. Tyto operace jsou reprezentace a transakční analýza dat a vzorů a manipulace s daty. K dispozici jsou také C implementace algoritmů těžby Apriori a Eclat.
Dokumentace
19. mboost
Další balíček R strojového učení pro datovou vědu je mboost. Tento modelový zesilovací balíček má algoritmus sestupu funkčního gradientu pro optimalizaci funkcí obecného rizika využitím regresních stromů nebo odhadů nejmenších čtverců jednotlivých komponent. Poskytuje také model interakce s potenciálně vysoce dimenzionálními daty.
Dokumentace
20. strana
Další balíček ve strojovém učení s R je párty. Tato výpočetní sada nástrojů se používá pro rekurzivní rozdělení na oddíly. Hlavní funkcí nebo jádrem tohoto balíčku strojového učení je ctree (). Jedná se o značně používanou funkci, která zkracuje dobu tréninku a zkreslení.
Syntaxe ctree () je:
ctree (vzorec, data)
Dokumentace
Končící myšlenky
R je tak prominentní programovací jazyk, který k prozkoumání dat používá statistické metody a grafy. Není nutné říkat, že tento jazyk má několik počtů balíčků strojového učení R, neuvěřitelný nástroj RStudio a snadno srozumitelnou syntaxi pro vývoj pokročilých projektů strojového učení. V balení R ml jsou některé výchozí hodnoty. Před použitím v programu musíte mít podrobné informace o různých možnostech. Pomocí těchto balíčků strojového učení může kdokoli vytvořit efektivní strojové učení nebo model datové vědy. A konečně, R je open-source jazyk a jeho balíčky se neustále rozšiřují.
Pokud máte nějaké návrhy nebo dotazy, zanechte prosím komentář v naší sekci komentářů. Tento článek můžete také sdílet se svými přáteli a rodinou prostřednictvím sociálních médií.


