Elasticsearch databáze
Elasticsearch je jednou z nejpopulárnějších databází NoSQL, která se používá k ukládání a vyhledávání textových dat. Je založen na technologii indexování Lucene a umožňuje vyhledávání vyhledávání v milisekundách na základě indexovaných dat.
Na webu Elasticsearch je definice:
Elasticsearch je distribuovaný otevřený zdroj, RESTful vyhledávací a analytický modul schopný řešit rostoucí počet případů použití.
To byla některá slova na vysoké úrovni o Elasticsearch. Pojďme zde podrobně pochopit pojmy.
- Distribuováno: Elasticsearch rozděluje data, která obsahuje, na více uzlů a použití otrokář algoritmus interně
- Klidný: Elasticsearch podporuje databázové dotazy prostřednictvím rozhraní REST API. To znamená, že můžeme používat jednoduchá volání HTTP a používat metody HTTP jako GET, POST, PUT, DELETE atd. pro přístup k datům.
- Vyhledávací a analytický modul: ES podporuje vysoce analytické dotazy spouštěné v systému, které mohou sestávat z agregovaných dotazů a více typů, jako jsou strukturované, nestrukturované a geo dotazy.
- Horizontálně škálovatelné: Tento druh škálování odkazuje na přidání více strojů do existujícího klastru. To znamená, že ES je schopen přijmout více uzlů ve svém klastru a neposkytnout žádné prostoje pro požadované upgrady systému. Podívejte se na obrázek níže, abyste pochopili koncepty škálování:
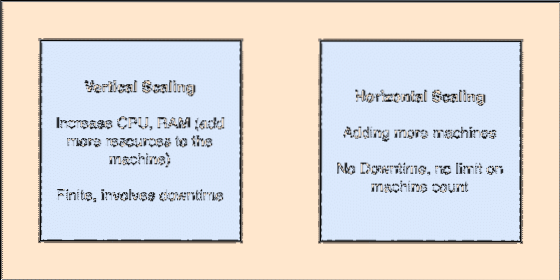
Vertikální a horizontální škálování
Začínáme s databází Elasticsearch
Chcete-li začít používat Elasticsearch, musí být na stroji nainstalován. Chcete-li to provést, přečtěte si téma Instalace ElasticSearch na Ubuntu.
Pokud chcete vyzkoušet příklady, které uvádíme dále v lekci, ujistěte se, že máte aktivní instalaci ElasticSearch.
Elasticsearch: Koncepty a komponenty
V této části uvidíme, jaké komponenty a koncepty leží v srdci Elasticsearch. Pochopení těchto konceptů je důležité k pochopení toho, jak ES funguje:
- Klastr: Klastr je kolekce serverových strojů (uzlů), která uchovává data. Data jsou rozdělena mezi více uzlů, takže je lze replikovat a na serveru ES Server se nestane Single Point of Failure (SPoF). Výchozí název clusteru je elasticsearch. Každý uzel v klastru se ke klastru připojuje pomocí adresy URL a názvu klastru, takže je důležité zachovat tento název odlišný a jasný.
- Uzel: Node machine is part of a server and is termed as a single machine. Ukládá data a poskytuje možnosti indexování a vyhledávání spolu s dalšími uzly do klastru.
Díky konceptu horizontálního škálování můžeme virtuálně přidat nekonečný počet uzlů do klastru ES, abychom mu poskytli mnohem větší sílu a možnosti indexování.
- Index: Rejstřík je sbírka dokumentů s poněkud podobnými vlastnostmi. Index je velmi podobný databázi v prostředí založeném na SQL.
- Typ: Typ se používá k oddělení dat mezi stejným indexem. Například Zákaznická databáze / rejstřík může mít více typů, jako je uživatel, typ_platby atd.
Všimněte si, že typy jsou od verze ES v6 zastaralé.0.0 dále. Přečtěte si, proč se to stalo.
- Dokument: Dokument je nejnižší úroveň jednotky, která představuje data. Představte si to jako objekt JSON, který obsahuje vaše data. V rejstříku je možné indexovat tolik dokumentů.
Typy vyhledávání v Elasticsearch
Elasticsearch je známý svými schopnostmi vyhledávání téměř v reálném čase a flexibilitou, kterou poskytuje s typem indexovaných a prohledávaných dat. Začněme studovat, jak používat vyhledávání s různými typy dat.
- Strukturované vyhledávání: Tento typ vyhledávání se spouští na datech, která mají předdefinovaný formát, jako jsou data, časy a čísla. S předdefinovaným formátem přichází flexibilita spouštění běžných operací, jako je porovnávání hodnot v rozsahu dat. Zajímavě, lze strukturovat i textová data. To se může stát, když má pole pevný počet hodnot. Například název databází může být, MySQL, MongoDB, Elasticsearch, Neo4J atd. U strukturovaného vyhledávání je odpověď na dotazy, které zpracováváme, buď ano, nebo ne.
- Fulltextové vyhledávání: Tento typ vyhledávání závisí na dvou důležitých faktorech, Relevantnost a Analýza. Pomocí Relevance určujeme, jak dobře se některá data shodují s dotazem, definováním skóre výsledných dokumentů. Toto skóre poskytuje samotný ES. Analýza označuje rozdělení textu na normalizované tokeny za účelem vytvoření obráceného indexu.
- Vyhledávání více polí: S rostoucím počtem analytických dotazů na uložená data v ES obvykle nečelíme jen jednoduchým dotazům na shodu. Požadavky narostly na spouštění dotazů, které se rozprostírají napříč více poli a mají bodovaný seřazený seznam dat, který nám vrátila samotná databáze. Tímto způsobem mohou být data koncovému uživateli poskytována mnohem efektivněji.
- Proimity Matching: Dotazy dnes nejsou jen o identifikaci, zda některá textová data obsahují jiný řetězec nebo ne. Jde o vytvoření vztahu mezi daty tak, aby bylo možné je skórovat a porovnat s kontextem, ve kterém se data porovnávají. Například:
- Míč zasáhl Johna
- John zasáhl míč
- John koupil nový Ball, který byl zasažen Jaen Garden
Při hledání vyhledávací dotaz najde všechny tři dokumenty Míč zasažen. Vyhledávání podle vzdálenosti nám může říci, jak daleko se tato dvě slova objevují ve stejném řádku nebo odstavci, kvůli kterému se shodují.
- Částečné shody: Často je potřeba spouštět částečné shody. Částečné párování nám umožňuje spouštět dotazy, které se částečně shodují. Abychom si to představili, podívejme se na podobné dotazy založené na SQL:
Dotazy SQL: Částečná shoda
KDE název jako „% john%“
AND jméno LIKE „% red%“
AND název LIKE „% garden%“V některých případech potřebujeme spustit pouze dotazy na částečnou shodu, i když je lze považovat za techniku hrubou silou.
Integrace s Kibanou
Pokud jde o analytický modul, obvykle musíme spouštět analytické dotazy v doméně Business-Intelligence (BI). Pokud jde o obchodní analytiky nebo datové analytiky, nebylo by fér předpokládat, že lidé znají programovací jazyk, když chtějí vizualizovat data přítomná v ES Clusteru. Tento problém řeší Kibana. Kibana nabízí tolik výhod pro BI, že lidé mohou skutečně vizualizovat data pomocí vynikajícího přizpůsobitelného řídicího panelu a vidět data nepřímo. Podívejme se zde na některé z jeho výhod.
Interaktivní grafy
Jádrem Kibany jsou interaktivní grafy, jako jsou tyto: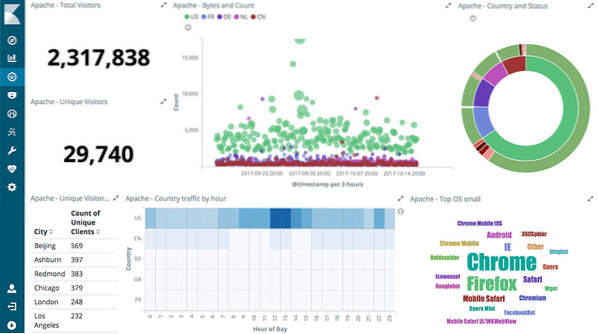
Kibana je podporována různými typy grafů, jako jsou výsečové grafy, výboje slunce, histogramy a mnoho dalšího, který využívá kompletní agregační schopnosti ES.
Podpora mapování
Kibana také podporuje kompletní geo-agregaci, která nám umožňuje geomapovat naše data. Není to super??!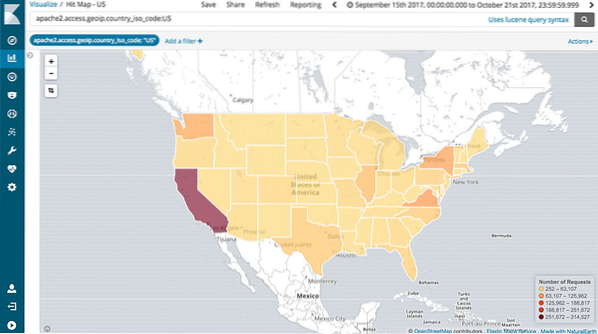
Předem sestavené agregace a filtry
S předem vytvořenými agregacemi a filtry je možné doslova fragmentovat, přetahovat a spouštět vysoce optimalizované dotazy v ovládacím panelu Kibana. Pouhými několika kliknutími je možné spouštět agregované dotazy a prezentovat výsledky ve formě interaktivních grafů.
Snadná distribuce řídicích panelů
S Kibanou je také velmi snadné sdílet řídicí panely mnohem širšímu publiku, aniž byste na řídicím panelu prováděli jakékoli změny pomocí režimu Pouze řídicí panel. Můžeme snadno vložit řídicí panely na naši interní wiki nebo webové stránky.
Hlavní obrázky pořízené z produktové stránky Kibana.
Používání Elasticsearch
Chcete-li zobrazit podrobnosti instance a informace o klastru, spusťte následující příkaz: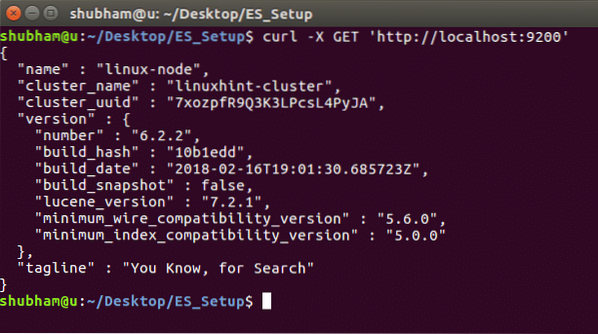
Nyní můžeme zkusit vložit některá data do ES pomocí následujícího příkazu:
Vkládání dat
zvlnění \-X POST 'http: // localhost: 9200 / linuxhint / ahoj / 1' \
-H 'Typ obsahu: aplikace / json' \
-d '"name": "LinuxHint"' \
S tímto příkazem se vrátíme:
Zkusme nyní získat data:
Získávání dat
curl -X ZÍSKEJTE 'http: // localhost: 9200 / linuxhint / ahoj / 1'Když spustíme tento příkaz, získáme následující výstup:
Závěr
V této lekci jsme se podívali na to, jak můžeme začít používat ElasticSearch, což je vynikající nástroj Analytics Engine a poskytuje vynikající podporu také pro vyhledávání ve volném textu v reálném čase.


