V této lekci uvidíme, co je Apache Kafka a jak funguje spolu s některými nejčastějšími případy použití. Apache Kafka byl původně vyvinut na LinkedIn v roce 2010 a od roku 2012 se stal projektem nejvyšší úrovně Apache. Má tři hlavní součásti:
- Vydavatel-předplatitel: Tato součást je zodpovědná za efektivní správu a doručování dat napříč uzly Kafka a spotřebitelskými aplikacemi, které se hodně rozšiřují (například doslovně).
- Připojte API: Connect API je nejužitečnější funkcí pro Kafku a umožňuje integraci Kafky s mnoha externími zdroji dat a datovými jímkami.
- Kafka proudy: Pomocí streamů Kafka můžeme uvažovat o zpracování příchozích dat v měřítku téměř v reálném čase.
V dalších částech si prostudujeme mnohem více konceptů Kafky. Pojďme kupředu.
Koncepty Apache Kafka
Než se podíváme hlouběji, musíme si důkladně promyslet některé koncepty v Apache Kafce. Zde jsou termíny, které bychom měli vědět, velmi stručně:
-
- Výrobce: Toto je aplikace, která odesílá zprávy Kafce
- Spotřebitel: Toto je aplikace, která spotřebovává data z Kafky
- Zpráva: Data, která jsou odesílána aplikací Producer do aplikace Consumer prostřednictvím Kafky
- Spojení: Kafka navazuje TCP spojení mezi clusterem Kafka a aplikacemi
- Téma: A Topic is a category to which sent data is tagged and deliver to interested consumer applications
- Tématický oddíl: Protože jediné téma může získat spoustu dat najednou, aby byla Kafka horizontálně škálovatelná, každé téma je rozděleno na oddíly a každý oddíl může žít na libovolném uzlovém stroji klastru. Zkusme to představit:
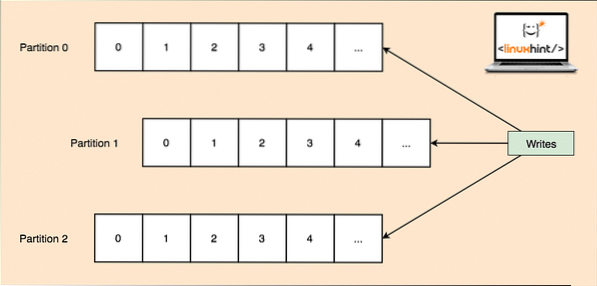
Tématické oddíly
- Repliky: Jak jsme studovali výše, téma je rozděleno na oddíly, každý záznam zprávy je replikován na více uzlech clusteru, aby se zachovalo pořadí a data každého záznamu v případě, že jeden z uzlů zemře.
- Skupiny spotřebitelů: Více spotřebitelů, kteří se zajímají o stejné téma, lze chovat ve skupině, která se nazývá skupina spotřebitelů
- Ofset: Kafka je škálovatelná, protože jsou to spotřebitelé, kteří ve skutečnosti ukládají, která zpráva byla načtena jako poslední, jako hodnota 'offset'. To znamená, že u stejného tématu může mít offset spotřebitele A hodnotu 5, což znamená, že bude muset dále zpracovávat šestý paket a u spotřebitele B může být hodnota offsetu 7, což znamená, že bude muset zpracovat další osmý paket. To úplně odstranilo závislost na samotném tématu pro ukládání těchto metadat souvisejících s každým spotřebitelem.
- Uzel: Uzel je jeden server v clusteru Apache Kafka.
- Klastr: Klastr je skupina uzlů i.E., skupina serverů.
Koncept Topic, Topic Partitions a offset lze také objasnit pomocí ilustrativního obrázku:
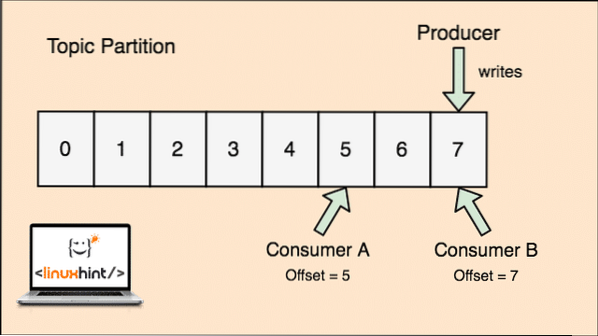
Tématický partion a offset pro spotřebitele v Apache Kafka
Apache Kafka as Publish-subscribe messaging system
S aplikací Kafka aplikace Producer publikují zprávy, které přicházejí na uzel Kafka, a nikoli přímo spotřebiteli. Z tohoto uzlu Kafka jsou zprávy spotřebovávány aplikacemi Consumer.
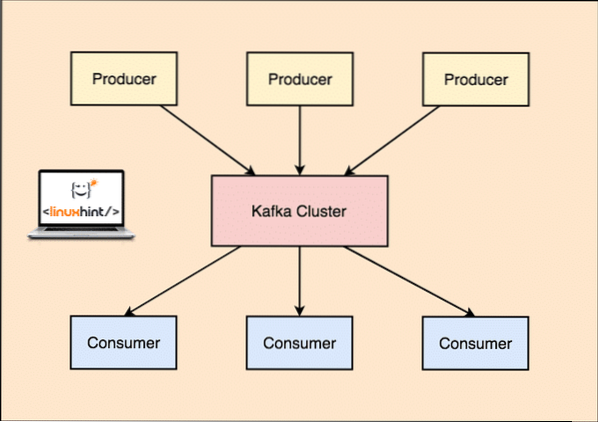
Výrobce a spotřebitel společnosti Kafka
Jelikož jediné téma může získat spoustu dat najednou, je každé téma rozděleno na, aby byla Kafka horizontálně škálovatelná oddíly a každý oddíl může žít na jakémkoli uzlovém stroji klastru.
Kafka Broker opět nevede záznamy o tom, který spotřebitel spotřeboval kolik paketů dat. To je odpovědnost spotřebitelů sledovat údaje, které spotřebovala. Z důvodu, že Kafka nesleduje potvrzení a zprávy každé spotřebitelské aplikace, může spravovat mnohem více spotřebitelů se zanedbatelným dopadem na propustnost. Ve výrobě se mnoho aplikací dokonce řídí vzorem dávkových spotřebitelů, což znamená, že spotřebitel spotřebuje všechny zprávy ve frontě v pravidelném časovém intervalu.
Instalace
Chcete-li začít používat Apache Kafka, musí být na počítači nainstalován. Chcete-li to provést, přečtěte si Instalovat Apache Kafka na Ubuntu.
Případ použití: Sledování používání webových stránek
Kafka je vynikající nástroj, který lze použít, když potřebujeme sledovat aktivitu na webu. Data pro sledování zahrnují mimo jiné zobrazení stránky, vyhledávání, nahrávání nebo jiné akce, které uživatelé mohou provést. Když je uživatel na webu, může při surfování na webu provést libovolný počet akcí.
Například když se nový uživatel zaregistruje na webu, může být aktivita sledována v jakém pořadí nový uživatel zkoumá funkce webu, pokud si uživatel nastaví svůj profil podle potřeby nebo upřednostňuje přímý skok k funkcím webová stránka. Kdykoli uživatel klikne na tlačítko, metadata pro toto tlačítko se shromáždí v datovém paketu a odešlou do clusteru Kafka, odkud analytická služba pro aplikaci může tato data shromažďovat a vytvářet užitečné informace o souvisejících datech. Pokud se podíváme na rozdělení úkolů do kroků, bude vypadat takto:
- Uživatel se zaregistruje na webu a vstoupí do řídicího panelu. Uživatel se pokusí o okamžitý přístup k prvku interakcí s tlačítkem.
- Webová aplikace vytvoří zprávu s těmito metadaty do tematické oblasti tématu „kliknout“.
- Zpráva se připojí k protokolu potvrzení a posun se zvýší
- Spotřebitel nyní může vytáhnout zprávu od Kafka Broker a ukázat využití webu v reálném čase a zobrazit minulá data, pokud resetuje jeho offset na možnou minulou hodnotu
Případ použití: Fronta zpráv
Apache Kafka je vynikající nástroj, který může fungovat jako náhrada za nástroje pro zprostředkování zpráv, jako je RabbitMQ. Asynchronní zasílání zpráv pomáhá při oddělení aplikací a vytváří vysoce škálovatelný systém.
Stejně jako koncept mikroslužeb můžeme namísto vytváření jedné velké aplikace můžeme aplikaci rozdělit na více částí a každá část má velmi konkrétní odpovědnost. Tímto způsobem lze různé části psát také ve zcela nezávislých programovacích jazycích! Kafka má zabudovaný systém dělení, replikace a odolnosti proti chybám, díky kterému je dobrý jako rozsáhlý systém zprostředkování zpráv.
V poslední době je Kafka také považována za velmi dobré řešení pro sběr protokolů, které dokáže spravovat broker serveru pro sběr souborů protokolů a poskytovat tyto soubory centrálnímu systému. Pomocí Kafky je možné vygenerovat jakoukoli událost, o které chcete, aby o ní věděla jakákoli jiná část vaší aplikace.
Používání Kafky na LinkedIn
Je zajímavé poznamenat, že Apache Kafka byl dříve viděn a používán jako způsob, kterým lze zajistit konzistentnost datových kanálů a prostřednictvím kterých se data přijímají do Hadoopu. Kafka fungovala excelentně, když bylo přítomno více zdrojů dat a cílů a poskytnutí samostatného procesu pro každou kombinaci zdroje a cíle nebylo možné. Jay Kreps, architekt Kafky z LinkedIn, popisuje tento známý problém dobře v příspěvku na blogu:
Moje vlastní zapojení do toho začalo kolem roku 2008 poté, co jsme odeslali náš obchod s klíči a hodnotou. Mým dalším projektem bylo pokusit se spustit fungující nastavení Hadoop a přesunout tam některé naše procesy doporučení. Vzhledem k tomu, že v této oblasti máme jen málo zkušeností, měli jsme přirozeně rozpočet na několik týdnů na získávání a odchod dat a zbytek času na implementaci efektních predikčních algoritmů. Tak začal dlouhý slog.
Apache Kafka a žlab
Pokud se přesunete k porovnání těchto dvou na základě jejich funkcí, najdete spoustu společných funkcí. Tady jsou některé z nich:
- Doporučuje se používat Kafku, pokud máte více aplikací, které spotřebovávají data, místo Flume, který je speciálně vytvořen pro integraci s Hadoop a lze jej použít pouze pro příjem dat do HDFS a HBase. Flume je optimalizován pro operace HDFS.
- U Kafky je nevýhodou, že je nutné kódovat producenty a aplikace pro spotřebitele, zatímco ve Flume má mnoho vestavěných zdrojů a propadů. To znamená, že pokud se stávající potřeby shodují s funkcemi Flume, doporučujeme vám kvůli úspoře času použít samotný Flume.
- Flume může konzumovat data za letu pomocí interceptorů. To může být důležité pro maskování a filtrování dat, zatímco Kafka potřebuje externí systém zpracování proudu.
- Je možné, že Kafka použije Flume jako spotřebitele, když potřebujeme přijímat data do HDFS a HBase. To znamená, že Kafka a Flume se integrují opravdu dobře.
- Společnosti Kakfa a Flume mohou zaručit nulovou ztrátu dat se správnou konfigurací, které je také snadné dosáhnout. Přesto upozorňujeme, že Flume nereplikuje události, což znamená, že pokud jeden z uzlů Flume selže, ztratíme přístup k událostem, dokud nebude disk obnoven
Závěr
V této lekci jsme se podívali na mnoho konceptů o Apache Kafce. Přečtěte si více příspěvků založených na Kafce zde.


